Timecop: Érase una vez las series temporales
En este artículo explicamos cómo gracias a Timecop (Auto ML en series temporales) podemos buscar anomalías o predecir series temporales en un gran número de casos de uso de una forma simple y rápida.

Introducción a las Time Series
Podemos definir las series temporales como la colección de observaciones de una o más variables recogidas en el tiempo con una periodicidad determinada que solemos representar en gráficos y del estudio de su relación y evolución analizar el comportamiento para, conociendo el pasado, en la medida de lo posible, tratar de predecir su futuro.
La característica fundamental es que las observaciones sucesivas deben tener una periodicidad conocida (hora, día, semana, mes, año…) y no son independientes entre sí porque las observaciones en un instante de tiempo dependen de los valores de la serie en el pasado.
¿Para qué se usan las Time Series?
Como hemos dicho, el análisis de las series temporales busca comprender el pasado para poder hacer una predicción sobre cómo será el futuro. Los campos más comunes son:
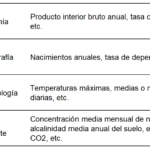
Componentes
Para ayudarnos a explicar el comportamiento de las series en el tiempo se hace un estudio descriptivo basado en descomponer sus variaciones en una o varias características básicas que llamamos componentes.
Los componentes o fuentes de variación que se consideran habitualmente son:
- Tendencia: Es el comportamiento o movimiento que se produce a largo plazo en relación a la media. La tendencia se identifica con un movimiento suave de la serie a largo plazo.
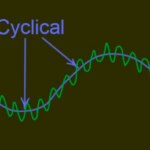
- Componente cíclica: Refleja comportamientos recurrentes en periodos superiores, por ejemplo un año, aunque no tienen por qué ser exactamente periódicos y con frecuencia resultan de la superposición de distintos efectos en periodos diferentes y muchas veces en series cortas no se consiguen separar de la tendencia.
- Componente estacional: Muchas series temporales presentan periodicidad de variación en cierto periodo (anual, mensual ...). Estos tipos de efectos son fáciles de entender y se pueden medir explícitamente o incluso se pueden eliminar del conjunto de los datos desestacionalizando la serie original.
- Componente aleatorio: También llamado irregular, son alteraciones de la serie sin una pauta periódica ni de tendencia claras. No suele tener incidencia en el resultado de la serie y se considera que está ocasionado por muchos factores de pequeña entidad.
La ciencia del dato
El trabajo habitual del científico de datos tiene dos fases diferenciadas, la primera y más importante para la calidad del resultado es el trabajo a realizar con los datos; selección de las fuentes, limpieza y preparación de los conjuntos de datos, o datasets y obtención de las features o características más importantes para en la segunda fase proceder a realizar la selección de los algoritmos, los entrenamientos adecuados generar las métrica y hacer las comparativas para finalmente llegar a generar una salida de resultados que aporten valor.
La primera fase es inherente al trabajo del científico de datos y en raras ocasiones no ocupará la mayor parte del tiempo, siendo común a cualquier proyecto de Machine Learning que se pretenda acometer.
Entrando ya en la segunda fase para generar una predicción con time series, hay tareas que debemos realizar para cada uno de los motores con los que vayamos a hacer el entrenamiento y validación para finalmente seleccionar el mejor motor y hacer las predicciones.
Auto ML
El aprendizaje automatizado (Auto ML) es un proceso automatizado para el diseño óptimo de modelos de ML que identifica la mejor configuración de sus hiperparámetros (ejemplos: número de capas de una red neuronal, profundidad de un árbol de decisión, etc.).
El aprendizaje automatizado se ha convertido en un tema de considerable interés en los últimos años, sin embargo, en contra de lo que por su nombre pudiera dar a entender, Auto ML no es ciencia de datos automatizada, ya que Incluso para las tareas predictivas, la ciencia de datos abarca mucho más. Sandro Saitta (Chief Industry Advisor at the Swiss Data Science Center) comentó: "El concepto erróneo proviene de la confusión entre todo el proceso de Data Science y las subtareas de preparación de datos (extracción de características, etc.) y modelado (selección de algoritmos, ajuste de hiperparámetros, etc.) que yo llamo Machine Learning".
Aún así, no cabe duda de que estas herramientas suponen una gran ayuda y han llegado al mundo de la ciencia de datos para quedarse.

Fuente : fast.ai **[http://www.fast.ai/2018/07/23/auto-ml-3/](http://www.fast.ai/2018/07/23/auto-ml-3/)

"The industry is gearing up to deliver AutoML as a Service. Google Cloud AutoML, Microsoft Custom Vision and Clarifai's image recognition service are early examples of automated ML services."
Fuente: Janakiram MSV - Forbes Contributor **[https://www.forbes.com/sites/janakirammsv/2018/04/15/why-automl-is-set-to-become-the-future-of-artificial-intelligence/#16d105a9780a](https://www.forbes.com/sites/janakirammsv/2018/04/15/why-automl-is-set-to-become-the-future-of-artificial-intelligence/#16d105a9780a)

Fuente : MIT News - MIT Laboratory for Information and Decision Systems - December 19, 2017 **[http://news.mit.edu/2017/auto-tuning-data-science-new-research-streamlines-machine-learning-1219](http://news.mit.edu/2017/auto-tuning-data-science-new-research-streamlines-machine-learning-1219)
Timecop: Time Series made simple
Hemos desarrollado Timecop como una herramienta internapero a la vez opensource para que pueda aportar valor a numerosos ámbitos. La idea es que todos aquellos sin conocimientos de estadística, ciencia de datos y el mundo del machine learning puedan introducir una serie de valores con pautas temporales y obtener cómo se han comportado en el pasado, cuál es la situación en el presente y una predicción de futuro.
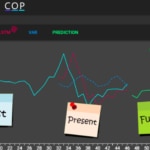
Timecop proporciona:
- Un listado de anomalías que se han producido en el Pasado: puntos donde se produce una desviación elevada.
- Estado actual de la time series: determinar si está en un estado anómalo actualmente
- Predicción de la timeseries: estimación de siguientes puntos de la serie.
Uso de Timecop
Serverless web service Restful
Uno de los objetivos de Timecop es la fácil integración con diferentes proyectos donde se puedan usar sus capacidades de detección de anomalías y predicción de forma simple y sin modificaciones en los procesos ya creados.
Las keys aceptadas en el JSON de entrada son:
- "data": serie con los datos de la timeseries
- "name": nombre de la serie para trabajar con motores antiguos y añadir a datos existentes en timecop
- "restart"(default:False): obviar todos los datos almacenados a la serie etiquetadas por el “name” y usar sólo los datos enviados en este JSON.
- _"desvmetric"(defautl:2): sensibilidad para la detección de anomalías
- "future"(default:5): número de puntos a predecir.
Para su fácil integración, Timecop se ofrece como web service que ofrece todos los resultados posibles en una única invocación.
- Invocación univariable (el análisis se hará a partir de una sola serie temporal)
Mediante un método POST se transmite una serie de números
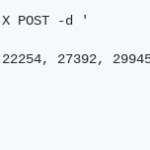
- Invocación multivariable (el análisis se hará basado en varias series temporales que influyen en la principal, sobre la que se harán las predicciones)
Mediante un método POST se transmiten todas las series necesarias para la predicción de la serie principal
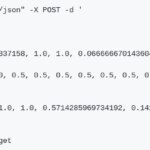
En ambos casos la respuesta se compone de un fichero json que contiene cuatro partes:
1.- Métricas del algoritmo ganador más preciso.
2.- Lista de puntos anómalos del pasado
3.- Estado actual de la serie (últimos 5 puntos): TRUE/FALSE y listado de puntos anómalos
4.- Predicción de los puntos de la serie configurable en la invocación.
A continuación podemos ver un ejemplo.

Web page
Para un uso no automático, hemos desarrollado una página web que puede invocar las dos URIs y visualizar su respuesta.
Una vez abierta la página podemos ver la zona de trabajo dividida en dos partes.
Data: datos de la serie y localización de Timecop
- URL: URI que invoca el servicio Timecop:- Univariable: http://127.0.0.1:5000/univariate- Multivariable:http://127.0.0.1:5000/multivariate
- Conjunto de datos, o DataSet:
Json con la serie (univariable) o conjunto de series (multivariable) con el que se invoca el web service. Para una mayor usabilidad hemos introducido la capacidad de leer un CSV y poder traducirlo en el formato JSON necesario.
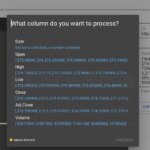
Si no se usa esta conversión de CSV a JSON, se pueden introducir los JSON en el siguiente formato.
* Univariable: Un ejemplo de JSON puede ser:
{"data":[15136, 16733, 20016, 17708, 18019, 19227, 22893, 23739, 21133, 22591, 26786, 29740,15028, 17977, 20008, 21354, 19498, 22125, 25817, 28779, 20960, 22254, 27392, 29945,16933, 17892,20533, 23569, 22417, 22084, 26580, 27454, 24081, 23451, 28991, 31386, 16896, 20045, 23471, 21747, 25621, 23859, 25500, 30998, 24475, 23145, 29701, 34365, 17556, 22077, 5702,22214,26886, 23191, 27831, 35406, 23195, 25110, 30009, 36242, 18450, 21845, 26488, 22394, 28057, 25451, 24872, 33424, 24052, 28449, 33533, 37351, 19969, 21701, 26249, 24493, 24603,26485, 30723, 34569, 26689, 26157, 32064, 38870, 21337, 19419, 23166, 28286, 24570, 24001, 33151, 24878, 26804, 28967, 33311, 40226, 20504, 23060, 23562, 27562, 23940, 24584,34303, 25517, 23494, 29095, 32903, 34379, 16991, 21109, 23740, 25552, 21752, 20294, 29009, 25500, 24166, 26960, 31222, 38641, 14672, 17543, 25453, 32683, 22449, 22316]}
* Multivariable: Un ejemplo con una serie principal (Main) y varias series que ayudan a la predicción de la serie principal:
{"timeseries":[ {"data": [0.9500000476837158, 1.0, 1.0, 0.06666667014360428, 0.42222222685813904, 0.0833333358168602, 0.09444444626569748, 0.23333333432674408, 0.0833333358168602, 0.9833333492279053, 0.04444444552063942, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.08888889104127884, 1.0, 0.9277778267860413, 0.5166666507720947, 0.9666666984558105, 0.6666666865348816, 0.3333333432674408, 0.9055556058883667, 0.8277778029441833, 0.5777778029441833, 1.0, 1.0, 0.08888889104127884, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.05000000074505806, 0.5166666507720947, 1.0, 0.03888889029622078, 0.03888889029622078, 0.4166666865348816, 0.03888889029622078, 0.03888889029622078, 0.06666667014360428, 0.5777778029441833, 0.3055555522441864, 1.0]}, {"data": [0.5, 1.0, 1.0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 1.0, 0.5, 0.5, 0.375, 0.5, 0.5, 0.5, 0.5, 0.5, 1.0, 1.0, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 0.5, 1.0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 1.0]}], "main": [0.8571429252624512, 1.0, 1.0, 0.5714285969734192, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 0.4285714626312256, 0.5714285969734192, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.8571429252624512, 1.0, 0.0, 0.1428571492433548, 0.2857142984867096, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 0.1428571492433548, 1.0, 1.0, 0.8571429252624512, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.8571429252624512, 0.4285714626312256, 1.0, 0.0, 0.0, 0.1428571492433548, 0.0, 0.0, 0.0, 0.1428571492433548, 0.1428571492433548, 1.0]}
Visualización de resultados
Los resultados se visualizan de la misma forma en univariante y multivariable.
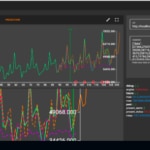
En la visualización se puede apreciar:
- la serie aportada (en verde en el ejemplo)
- los resultados de los diferentes algoritmos en la fase de test (punteados)
- la mejor predicción existente (en naranja)
- anomalías(puntos rojos)
Preparado para producción:
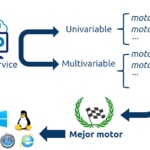
El principio básico de Timecop es la generación de tantas predicciones como sea posible y posteriormente seleccionar la que mejor se adapte.
Timecop pretende comparar los mejores modelos de cada tipo de algoritmo. Para ello, se toma el 70% de la serie para el entrenamiento y el 30% para los tests de todos los modelos.
Una vez seleccionado el mejor modelo con cada algoritmo, se compara la métrica elegida ( en nuestro caso, ahora Mínimo Error Absoluto, o MAE en inglés) y se presenta la predicción y anomalías de este modelo ganador.
Pero esa búsqueda del mejor algoritmo conlleva un tiempo, consumo de CPU y RAM muy elevados que pueden no ser requeridos en todo momento.
Para su uso en producción, no siempre se requiere la búsqueda del mejor algoritmo, ya que la solución óptima suele ser la reutilización del motor obtenido con anterioridad. Si no se búsqueda el mejor algoritmo la respuesta se realiza en segundos en vez de minutos.
Para ello, se han incluido en la invocación los siguientes argumentos:
- train(defecto:True): indicar que se buscará el mejor algoritmo.
- restart(defecto:False): indica que no se desea añadir los datos enviados a los datos asistentes a la serie almacenada en timecop. De esta forma, se puede reiniciar la información que existe en timecop.
Arquitectura
La necesidad de gestionar muchas timeseries en entornos productivos de una forma ágil exige a timecop a disponer de un backend robusto y capaz de dimensionarse de forma simple ante miles de peticiones.
Para ello, Timecop cuenta con un backend celery para poder ejecutar tantas peticiones como sean necesarias. De esta forma, nos permite:
- aislar el procesamiento en la búsqueda de los mejores algoritmos, permitiendo una respuesta asíncrona que no penalice el rendimiento de la plataforma
- incrementar el número de workers, para se pueda incrementar el número de peticiones atendidas de forma horizontal en diferentes máquinas/instancias.
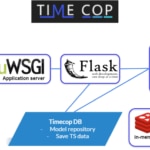
Además de utilizar el backend se ha realizado un docker para su uso de forma simple. El disponer de una solución basada en contenedores docker nos permite una gestión adaptada a los nuevos entornos de nube, escalado horizontal, gestión de versionados, y su rápido despliegue.
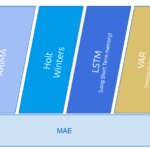
Algoritmos utilizados
De una manera transparente para el usuario, Timecop realiza el trabajo de detectar la estacionalidad de las series, realizar el entrenamiento y validación de los diferentes algoritmos, aplicar la métrica más adecuada, seleccionar el algoritmo con mejores resultados y generar el gráfico de salida.
Actualmente Timecop realiza el proceso usando los siguientes motores; ARIMA, Holt-Winters, LSTM (Long Short Term memory) y VAR (Vector AutoRegression), siendo estos dos últimos aplicables también para series multivariable.
ARIMA (AutoRegressive Integrated Moving Average)
Es un modelo dinámico de series temporales que utiliza variaciones y regresiones de datos estadísticos para encontrar patrones que permitan hacer una predicción de futuro.
Es utilizado en series temporales estacionales siendo inviable su uso para series no estacionarias.
En los modelos ARIMA(p,d,q), p representa el orden del proceso autorregresivo, d el número de diferencias que son necesarias para que el proceso sea estacionario y q representa el orden del proceso de medias móviles.
El modelo ARIMA se puede representar así:
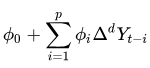
Holt-Winters (Suavizamiento Exponencial):
Es una manera de pronosticar la demanda de un producto en un periodo dado, Holt-Winters considera nivel, tendencia y estacionalidad de una determinada serie de tiempos. Incorpora un conjunto de procedimientos que conforman el núcleo de la familia de series temporales de suavizamiento exponencial.
Igual que el modelo ARIMA está pensado principalmente para series estacionarias, pero con la ventaja de que su coste computacional es inferior.
A diferencia de muchas otras técnicas, el modelo Holt-Winters puede adaptarse fácilmente a cambios y tendencias, así como a patrones estacionales. tiene la ventaja de ser fácil de adaptarse a medida que nueva información real está disponible, y en comparación con otras técnicas como ARIMA, el tiempo necesario para calcular el pronóstico es considerablemente más rápido
LSTM (Long Short Term memory)
El modelo LSTM es un caso especial de redes neuronales tradicionales y son ampliamente utilizadas en problemas de predicción en series temporales debido a que su diseño permite recordar la información durante largos períodos y facilita la tarea de hacer estimaciones futuras empleando períodos de registros históricos.
A diferencia de las redes neuronales tradicionales, en lugar de poseer neuronas de manera clásica, las redes LSTM, pertenecientes a la clase de Redes Neuronales Recurrentes (RNN en inglés), utilizan también su propia salida como input para la siguiente predicción, de modo recurrente, permitiendo así captura el componente temporal de la entrada. Estos bloques de memoria facilitan la tarea de recordar valores, por lo tanto, el valor almacenado no es reemplazado (al menos a corto plazo) de forma iterativa en el tiempo, y el término de gradiente no tiende a desaparecer cuando se aplica la retro-propagación durante el proceso de entrenamiento, tal y como sucede en el uso de las redes neuronales clásicas.
VAR (vector autorregresivo)
Propone un sistema de tantas ecuaciones como series a analizar o predecir, pero en el que no se distingue entre variables endógenas y exógenas. Así, cada variable es explicada por los retardos de sí misma (como en un modelo AR) y por los retardos de las demás variables. Se configura entonces un sistema de ecuaciones autorregresivas o un vector autorregresivo (VAR). Es muy útil cuando existe evidencia de simultaneidad entre un grupo de variables, y que sus relaciones se transmiten a lo largo de un determinado número de periodos.
Resumen
Con Timecop basta con introducir la serie numérica a analizar y predecir, y realiza todas las tareas previas necesarias para que los datos puedan ser analizados y procesados por los motores
Métricas
La clave de un sistema de Auto ML como Timecop reside en la comparación de los algoritmos y modelos entrenados y la selección del que mejor se adapte a las necesidades de la timeseries analizada. Para ello, es vital seleccionar una métrica precisa que permita una comparación correcta entre los diversos algoritmos de predicción de timeseries.
Timecop realiza la comparación de los diversos algoritmos sobre un 30% de la timeseries, seleccionando el motor que tenga el MAE menor.
En el caso de Timecop usamos MAE en el conjunto de entrenamiento de la serie temporal pero proporcionamos como salida un conjunto de las más conocidas como son:
MAE (Mean Absolute Error)
El error medio absoluto mide la magnitud promedio de los errores en un conjunto de predicciones, en valor absoluto. Es el promedio sobre la muestra de prueba de las diferencias absolutas entre la predicción y la observación real donde todas las diferencias individuales tienen el mismo peso.
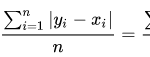
MAPE (Mean Absolute Percentage Error)
El error medio de porcentaje absoluto mide el tamaño del error (absoluto) en términos porcentuales. El hecho que se estime una magnitud del error porcentual lo hace un indicador frecuentemente utilizado por los encargados de elaborar pronósticos debido a su fácil interpretación. Incluso es útil cuando no se conoce el volumen de demanda del producto dado que es una medida relativa
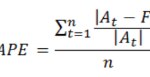
MSE (Mean Squared Error)
El error cuadrático medio toma las distancias desde los puntos predichos hasta los puntos reales (estas distancias son los "errores") y se cuadran. La cuadratura es necesaria para eliminar cualquier signo negativo.
Al tener el cuadrado de la diferencia da más peso a los outliers, es decir, a los puntos con diferencias más grandes.
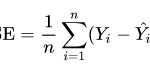
RMSE (Root Mean Squared Error)
RMSE es una regla de puntuación cuadrática que también mide la magnitud promedio del error. Es la raíz cuadrada del promedio de las diferencias cuadradas entre la predicción y la observación real.
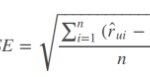
Conclusiones
Timecop quiere cubrir un hueco en el mundo del Auto Machine Learning para simplificar el trabajo de los científicos de datos en series temporales.
Pretende reducir el trabajo no creativo de seleccionar el mejor modelo en función de las características de la serie temporal, dejando más tiempo a los científicos de datos a la selección de las features y su integración en entornos que aporten el valor adecuado.
Permite realizar análisis temporales en cortos períodos de tiempo, pudiendo conocer las anomalías y predicciones de cientos de series a la vez y abriendo nuevos mundos para la comparación de evoluciones de miles y millones de series de una forma sencilla que hasta la fecha no existía.
PD: gracias a todos los que han colaborado para que Timecop llegue a donde está
Referencias
- Proyecto Timecop: https://github.com/BBVA/timecop