Seamless Networking para Container Orchestration Engines
En un entorno con diferentes Motores de Orquestación de Contenedores entre los que elegir (COEs, por sus siglas en inglés), como Kubernetes, OpenShift, DC/OS, Nomad o Swarm, hay ocasiones en las que la solución óptima para desplegar varias aplicaciones requiere de más de un COE. Cada uno de ellos tiene sus puntos fuertes y están enfocados a un tipo de tareas o trabajos específicos. Por ejemplo, Kubernetes está especialmente preparado para desplegar microservicios de una naturaleza muy dinámica. Sin embargo, en un entorno tan dinámico es complicado mantener un sistema de base de datos, para lo cual es más apropiado un sistema como DC/OS.

En BBVA Labs nos preguntamos cuál sería la mejor forma de hacer convivir varios de estos COEs, aprovechando elementos comunes y permitiendo que cada uno de ellos destaque en lo que más aporta valor. Hemos estudiado cómo desplegar de forma sencilla e independiente diferentes COEs, permitiendo la comunicación entre ellos en cuanto se despliegan out-of-the-box.
Nuestro objetivo es permitir que múltiples COEs sean capaces de coexistir independientemente, poder dimensionarlos de manera individual, o hacerlos escalar según nuestras necesidades.
Las soluciones de conectividad específicas que hemos empleado se basan en protocolos de enrutado estándar. Cualquiera de los productos de software que los implementan pueden ser sustituidas por otros, siempre que se basen en los mismos protocolos. De esta forma aseguramos la interoperabilidad, independientemente de fabricantes de hardware o software.
Introducción
Cuando desplegamos una solución para orquestar contenedores (COE), cada uno de ellos tiene su propia estrategia para proveer de almacenamiento, seguridad o conectividad de red. Cuando se requiere extender la solución genérica que proveen los COEs, la mayoría permiten la integración con productos de terceros mediante una interfaz más o menos estandarizada. Por ejemplo, para las redes tenemos Calico, Flannel o Weave usando el plugin estándar de CNI (Container Network Interface), y para almacenamiento GlusterFS, Ceph o Cinder bajo el API de storage class.
El objetivo de este experimento es validar una arquitectura común de comunicaciones entre COEs que pueda ser sencilla y basada en mecanismos de red estándar. Todo ello manteniendo el sistema de despliegue y los elementos propios de cada COE. De esta forma, permitimos que cada COE pueda evolucionar de manera independiente y los servicios que se desplieguen en cada uno tengan su propio ciclo de vida.
Además, queremos que la conectividad entre servicios albergados en diferentes COEs sea transparente, permitiendo que los métodos de publicación de servicios al exterior sean consumidos desde redes ajenas al COE desde el que se publica un servicio (redes públicas, o redes externas). De esta forma, una aplicación basada en microservicios podría desplegar cada uno de sus componentes en el COE en el que le aporte más valor.
Arquitectura
Los COEs crean nuevas redes de forma muy dinámica, acorde con la naturaleza de los contenedores. Para poder comunicar los servicios alojados entre COEs distintos podemos tomar varios caminos:
- Tratarlos de forma totalmente independiente, y permitir que los servicios publicados en cada COE sean accesibles desde cualquier sitio. Este método es el más usado en clouds públicas como las de Amazon o Google, ya que es sencillo publicar servicios gracias a la integración con Load Balancers del propio proveedor de cloud (AWS Elastic Load Balancer o Google Cloud Load Balancer).
Deberemos asegurarnos de que nuestro COE se integra con alguno de estos servicios de balanceador del proveedor de cloud, o de si el COE tiene su propio servicio de balanceo que pueda ser expuesto (asignándole una IP pública). En este último caso, somos responsables también de la escalabilidad del servicio de balanceo. - Usar una solución de red / Software Defined Networking (SDN) común que nos permita interconectar los mundos de cada uno de los COEs. El inconveniente es que nuestro producto de SDN debe integrarse específicamente con cada COE. En el momento que queramos usar uno no compatible, tendremos un grave problema: la solución de red nos bloquearía su adopción.
- Hacer uso del routing tradicional, y habilitar que cualquier red que se cree en un COE sea accesible desde otro COE de forma automática. Este método nos debería permitir que cualquier par de servicios en COEs distintos sean capaces de comunicarse entre sí.
La primera solución es muy dependiente del proveedor de cloud, y no siempre es una opción si queremos usar nuestra propia infraestructura. En la segunda debemos asegurarnos de la compatibilidad entre el producto y cada COE, asumiendo que tendremos un vendor lock-in perpetuo con el proveedor de la solución de SDN. La tercera opción (usar routing tradicional) nos parecía un buen camino a explorar, siempre y cuando seamos capaces de permitir que las rutas se comuniquen y propaguen a la velocidad que requieren los entornos de orquestación de contenedores.
Las comunicaciones dentro de un COE
Aunque la forma de dotar de comunicaciones a los componentes de un servicio o aplicación dependen en gran medida de las particularidades de cada COE, podemos simplificar la arquitectura común de los COEs en tres capas:
- A cada instancia de las múltiples e idénticas que componen un servicio determinado (pod/worker/…, el nombre depende del COE) se les asigna una IP en un rango privado al COE. Generalmente la red asignada depende de en qué host se ejecuta la instancia.
- Todo servicio (conjunto de instancias que realizan el mismo trabajo) tiene una IP en la que expone su funcionalidad para ser consumido por otros servicios. Nos interesa que esta red sea accesible desde otros servicios y, en nuestro caso, desde servicios ubicados en otros COEs.
- Si un servicio se quiere publicar fuera del ámbito del COE (el frontend, el API público de nuestra aplicación, etc), se le asigna una IP en un rango público y/o se coloca un balanceador (load balancer) delante para el reparto de carga.
Si el servicio a publicar es HTTP(S), deberemos usar un proxy HTTP que permita redirigir peticiones basadas en la URL a los contenedores que deben aceptar esta petición.
Si el servicio es TCP o UDP, la solución consiste en provisionar un balanceador (load balancer) que distribuya las peticiones en función del puerto que asignemos a nuestro servicio.
En cualquier caso, la configuración del proxy o LB debe ser automática y estar integrada con el COE en el que da servicio.
Una vez publicados de esta manera, para comunicar dos servicios entre sí se hacen peticiones a este stack. A menudo estas comunicaciones entre aplicaciones no son de servicios expuestos al exterior (DBs, brokers de mensajería, etc). Por lo tanto, si usamos el mismo sistema para comunicar servicios «internos» que el de publicación de servicios públicos, estaremos:
- Impidiendo la compatibilidad con aplicaciones que no puedan ser expuestas mediante un proxy o load balancer.
- Desperdiciando direccionamiento público, o desperdiciando recursos en el load balancer o en el proxy. Ambos elementos son escasos y caros.
Routing entre COEs
Como estamos viendo, las redes en un COE son extremadamente dinámicas: se crean y destruyen rutas para llegar a los contenedores de un servicio a medida que escalan para atender la demanda en cada momento. Por suerte para nosotros, de todo eso se ocupa el scheduler de cada COE dentro de su pequeño mundo. Pero, ¿y de cara al exterior?
Dado un servicio desplegado en un COE, queremos poder acceder a él desde otro COE de forma transparente. Para esto, cada host debe saber cómo llegar hasta el servicio publicado en otro COE. Por lo tanto, necesitamos una forma de comunicar la información de rutas a cada uno de los nodos para conocer el camino.
Los nodos también son dinámicos: podemos añadir y quitar nodos a nuestro COE según sea necesario. No es una operación tan dinámica como el escalado de los servicios, pero no podemos confiar en que sea una topología fija. Cada vez que se provisiona un nuevo nodo, se crea una nueva red a la que se conectarán los contenedores que corran en ese nodo. Cada vez que un contenedor y/o un servicio se da de alta, todos los nodos deben saber cómo llegar a él.
En este punto es donde entran en juego los protocolos de routing, como BGP.
Enter BGP
BGP juega un papel crítico en las comunicaciones en Internet. Facilita el intercambio de información sobre redes IP y la comunicación entre lo que se llama en la jerga de BGP sistemas autónomos(AS). BGP es ampliamente utilizado para publicar redes tanto en Internet como dentro de los data center modernos, lo que lo hace un protocolo muy versátil y popular.
BGP intercambia información de enrutamiento entre sistemas autónomos a la vez que garantiza una elección de rutas libres de bucles. Es el protocolo principal de publicación de rutas utilizado por las compañías más importantes en Internet.
Algunas de las ventajas de usar un protocolo estándar y buscar la simplicidad retirando todas las capas de complejidad innecesarias son:
- No es necesario crear una red de overlay (y encapsular), ni por tanto hacer uso de túneles o tablas VRF: Simple, eficiente y sin ocultar el tráfico.
- No necesitamos realizar NAT: cualquier servicio puede llegar a donde nosotros queramos que llegue sin tener que hacer una gestión específica. Únicamente estamos creando los caminos para que el tráfico fluya de forma natural.
Tenemos un protocolo de publicación de rutas que es dinámico y ampliamente utilizado; Ahora necesitamos la forma de conseguir que sea sencillo de integrar con los COEs:
- Podemos instalar y configurar un daemon de BGP en todos los hosts de la infraestructura, y que se encargue de comunicar las redes que gestionan al resto de los nodos. BIRD es un daemon para GNU/Linux que nos proporciona una pila de protocolos de routing. A continuación habría que configurarlo dinámicamente usando alguna herramienta de gestión de la configuración como Ansible, Puppet o similar para mantener correctamente actualizado y configurado este daemon en cada nodo.
- Otra opción, es recurrir a soluciones que implementan BGP y se integran en cada COE. Al contrario que la solución de usar una SDN para todos los COEs, esta solución se ciñe a cada COE, pero estableciendo un marco común de comunicaciones basado en BGP con el exterior (inter-COE). Por lo tanto, si una solución no es compatible con un COE, podemos usar otra diferente siempre y cuando hable BGP.
Independientemente de la solución que queramos adoptar, tenemos que pensar cómo vamos a comunicar las rutas de un COE a las de sus vecinos (inter-COE). En BGP, es necesario que cada nodo que quiere consumir y/o publicar redes tenga explícitamente configurado con qué vecinos se debe comunicar (básicamente, conocer su IP). Recordemos que los vecinos también pueden ser dinámicamente creados y destruidos. Se nos ofrecen dos opciones para mantener esta topología:
- Topología full-mesh: (Re)configurar cada nodo cada vez que haya un cambio en la topología (añadir/quitar COE o nodos), añadiendo o borrando la información de sus vecinos.
- Usar un elemento común al que todos los COEs acudan para conocer la topología de los demás. Este elemento común se denomina route-reflector, y puede ser cualquier elemento que implemente el protocolo BGP, como un router tradicional, un switch L3 TOR (Top-of-the-Rack), un router virtualizado o un contenedor con un daemon de BGP corriendo fuera de cualquier COE.
Calico
Calico es una solución de comunicaciones que implementa BGP, tiene fácil configuración y se integra con los COEs elegidos para hacer esta prueba: Kubernetes y DC/OS. Además, provee conectividad de red segura para contenedores y máquinas virtuales y permite asignación de IP dinámica.
Calico implementa BGP para transmitir las rutas de los servicios o contenedores que despliega en cada uno de sus nodos al resto del cluster, por lo que si además hacemos que esas rutas se comuniquen fuera del COE, tendremos una solución válida para nuestro propósito.
GoBGP
GoBGP es una implementación open-source implementada en Golang del protocolo BGP. Permite ser configurado de múltiples maneras, y posee un API gRPC.
En nuestro caso lo hemos empleado en el laboratorio como BGP route-reflector para transmitir las rutas de los servicios entre los diferentes COEs. Esta aproximación nos da la flexibilidad suficiente para probar el modelo sin depender de un stack de router completo: podemos configurarlo dinámicamente según vamos realizando pruebas de integración.
En un entorno destinado a producción usaríamos un hardware específico de red para realizar este trabajo.
El Experimento
Infraestructura
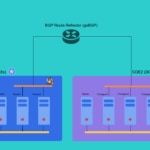
Para el experimento contamos con varias máquinas distribuidas de la siguiente manera:
Kubernetes 1 Controller 3 Workers DC/OS 1 Master 2 Private Agents 1 Public Agent
Adicionalmente, contamos con un contenedor de GoBGP conectado a esta red para actuar como router/route-reflector y así comunicar las rutas entre COEs.
Todos los elementos de esta infraestructura los hemos ubicado en una red con direccionamiento 172.16.18.0/24.
Configuración Básica
COEs: Kubernetes y DC/OS:
- En Kubernetes se ha instalado kube-dns, kube-dashboard y heapster en un despliegue canónico según su documentación oficial.
- DC/OS cuenta con su orquestador propio (Marathon) para gestionar las tareas internas. Hemos instalado un segundo framework de Marathon para usuarios (marathon-user), un marathon-lb apuntando a este marathon-user, y un cluster de etcd. Todos han sido instalados a partir del repo Universe (repositorio público de frameworks de DC/OS) y con modificaciones mínimas.
Es una buena práctica usar un segundo Marathon para usuarios, ya que separamos los contenedores ejecutados por el sistema de los ejecutados por los usuarios manteniendo una mejor segmentación de los recursos a la vez que mejoramos la seguridad. Además, facilita la comunicación entre Calico y estos contenedores. El marathon-user se despliega en los nodos privados de DC/OS junto con los nodos de Calico.
BGP: Route-Reflector y configuración común
Cuando configuramos BGP, la configuración de vecindad ha de ser recíproca: debemos realizar configuración tanto en los nodos como en el router. En el contenedor de GoBGP esto lo hemos realizado configurando cada nodo como vecino cuando lo desplegamos. En cada COE configuramos Calico para que distribuya la información de dónde está el BGP peer.
Hemos asignado la subrred 192.168.0.0/16 (65534 hosts posibles) a toda la infraestructura, dividida en dos segmentos (/17) para cada COE:
- La subred 192.168.0.0/17 para Kubernetes.
- La subrred 192.168.128.0/17 para DC/OS.
Por simplicidad, todos los elementos de la infraestructura pertenecen al mismo Autonomous System (AS) que el asignado a los COEs (ASN 64511). En función del tamaño de nuestro entorno y del grado de aislamiento de red que queramos, podremos asignar un AS por COE, por rack o por servidor.
La configuración aplicada en el daemon de GoBGP es la siguiente, aunque añadiendo el resto de nodos:
[global.config] as = 64511 router-id = "${ROUTER_IP}"
[[neighbors]] [neighbors.config] neighbor-address = "172.16.18.33" peer-as = 64511 [neighbors.route-reflector.config] route-reflector-client = true route-reflector-cluster-id = "${ROUTER_IP}"
Calico
Hemos realizado una instalación de Calico para cada uno de los orquestadores. Calico ha sido configurado siguiendo la documentación oficial para cada uno de ellos. En cuanto a la configuración específica, sólo hemos tenido que definir en la configuración de Calico para cada COE:
- La subred asignada
- El Autonomous System Number (ASN) 64511 de BGP
- La información del route reflector que tiene como vecino.
- Deshabilitar cualquier tipo de NATing y encapsulamiento (IP-on-IP).
En nuestro caso, esta es la configuración utilizada:
-
- apiVersion: v1 kind: ipPool metadata: cidr: 192.168.0.0/17 spec: nat-outgoing: false ipip: enabled: false
- apiVersion: v1 kind: bgpPeer metadata: peerIP: 172.16.18.32 scope: global spec: asNumber: 64511
Configuración de Policy y Profile de Calico
Calico es una solución completa de comunicación, que provee también de funciones de seguridad que complementan o se integran con las que ofrece el COE.
Calico utiliza Profiles y Policies para gestionar el acceso por red. Para más detalle, ver la documentación.
Solo con la configuración anterior no es suficiente para permitir la comunicación entre COEs. Las políticas de seguridad (policies) por defecto de Calico descartan todo el tráfico proveniente de fuera del COE.
No es objeto de este estudio probar las capacidades de seguridad de Calico, tan solo queremos probar la comunicación entre COEs. Para realizar nuestras pruebas, hemos permitido todo tipo de tráfico, aplicando las políticas de seguridad más permisivas posibles en Calico:
- apiVersion: v1 kind: policy metadata: name: allow-all spec: types: ingress egress ingress: action: allow egress: action: allow
También hemos aplicado la misma regla para los perfiles de calico:
- apiVersion: v1 kind: profile metadata: name: calico-open spec: egress: action: allow ingress: action: allow
Proceso de propagación de rutas
Una vez que tenemos los COEs configurados, desplegamos Calico en cada uno de ellos y tenemos un route-reflector configurado, veamos qué va ocurriendo.
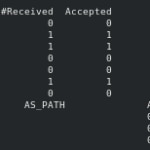
Inicialmente, cuando los nodos de ningún COE están desplegados, podemos ver como nuestro route-reflector, que debe tener toda la información de rutas, muestra que no están conectados y tampoco se comparten rutas.
Peer AS Up/Down State |#Received Accepted 172.16.18.33 64511 never Active | 0 0 172.16.18.34 64511 never Active | 0 0 172.16.18.35 64511 never Active | 0 0 172.16.18.36 64511 never Active | 0 0 172.16.18.43 64511 never Active | 0 0 172.16.18.44 64511 never Active | 0 0 172.16.18.45 64511 never Active | 0 0 Network not in table
Una vez que hemos desplegado Kubernetes, podemos ver cómo se empiezan a compartir algunas rutas de los servicios iniciales que utilizan la red de Calico. Estos servicios se encuentran en los nodos worker (172.16.18.34 y 172.16.18.35). Calico ha reservado una subred de la que tiene asignada en cada nodo (192.18.55.128/26 y 192.168.119.192/26) y las ha comunicado al route-reflector
Peer AS Up/Down State |#Received Accepted
172.16.18.33 64511 00:00:30 Establ | 0 0
172.16.18.34 64511 00:00:30 Establ | 1 1
172.16.18.35 64511 00:00:30 Establ | 1 1
172.16.18.36 64511 never Active | 0 0
172.16.18.43 64511 never Active | 0 0
172.16.18.44 64511 never Active | 0 0
172.16.18.45 64511 never Active | 0 0
Network Next Hop AS_PATH Age Attrs
> 192.168.55.128/26 172.16.18.34 00:00:30 [{Origin: i} {LocalPref: 100}]
> 192.168.119.192/26 172.16.18.35 00:00:30 [{Origin: i} {LocalPref: 100}]
En DC/OS ninguno de sus servicios internos utiliza Calico inicialmente. Por tanto, hemos desplegado un servicio que se está ejecutando en el Private Agent 2. Así como pasó en Kubernetes, Calico ha reservado una subred (192.168.158.192/26) de la que tiene asignada (192.168.128.0/17) para asignarle una IP a este contenedor (192.168.158.192) y la ha comunicado al route-reflector.
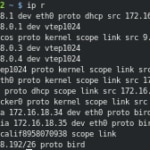
Si accedemos a los respectivos nodos y consultamos su tabla de rutas, podemos ver lo siguiente:
En el Private Agent 2 de DC/OS hemos recibido las rutas de los servicios expuestos Kubernetes propagadas por medio del route-reflector (protocolo BIRD), así como la IP e interfaz asociadas a nuestro contenedor con Nginx. Esto sucedería de la misma manera con el resto de nodos de DC/OS:
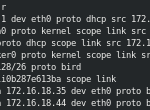
El Worker 1 de Kubernetes ha recibido las rutas del otro nodo de Kubernetes con servicios desplegados, como el del contenedor de Nginx desplegado en DC/OS usando el mismo mecanismo (protocolo BIRD):
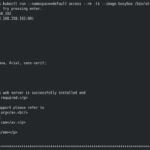
Por último hemos realizado la comprobación de que podemos acceder al contenedor de Nginx desde Kubernetes con un simple WGET:
Conclusión
En este experimento hemos podido comprobar la factibilidad de conectar dos sistemas disjuntos con redes propias utilizando protocolos y mecanismos estándar utilizados en la red de redes, Internet.
Aunque en este caso hemos conectado directamente las redes de contenedores de Kubernetes (red de pods) y DC/OS, lo interesante es que es posible extender este experimento para conectar las redes de servicios balanceados (red de Servicios en Kubernetes y red de Internal Marathon-LB en DC/OS).
Así mismo, se puede utilizar una solución de DNS que agrupe los servicios expuestos en cada COE y simplifique el acceso de uno a otro. Muchos COEs ya incorporan su propia solución de service discovery, pero el reto estaría en interconectarlos entre sí.
No obstante, hay que recordar que cualquier aumento en la complejidad debe estar justificado. En este caso, sólo en un entorno en el que las necesidades justifiquen el despliegue de más de un COE deberíamos plantearnos una solución de este tipo. Además, esta solución también nos obliga a conocer BGP, que si bien no es complejo de aprender, hay que entenderlo para saber cómo desplegarlo y controlar la escalabilidad de nuestro entorno.