Redes neuronales distribuidas con Tensorflow: Conclusiones
El entrenamiento de redes neuronales plantea grandes exigencias tanto del punto de vista de temporal como de capacidad de procesamiento, incluso para los estándares actuales. Existen dos maneras de reducir la cantidad de tiempo necesaria: recurriendo a máquinas más potentes o a un mayor número de ellas.
Para la primera opción existe la posibilidad de recurrir al uso de hardware dedicado como unidades de procesamiento gráfico (GPU o grafic processing units), o incluso FPGAs y TPUs – tensor programming unit en el futuro. Pero también puede lograrse dividiendo la tarea entre equipos de uso normal, como las que se utilizan en los sistemas basados en la nube.
Este documento resume las conclusiones alcanzadas tras investigar el uso de redes neuronales distribuidas.

El método utilizado más frecuentemente por la comunidad académica para entrenar redes neuronales está basado en sistemas de hardware compuestos por grupos cada vez más amplios de GPUs más potentes. Aun cuando, probablemente, adquirir un número limitado de este tipo de máquinas no sea demasiado complicado, para una institución financiera multinacional, a partir de cierto número de equipos, la adquisición podría llevar demasiado tiempo. Así, el desarrollo de una capacidad de procesamiento equiparable utilizando equipos de uso general ya adquiridos emerge como alternativa atractiva cuando surja la necesidad de dar respuesta a las necesidades del mercado en plazos razonables de tiempo.
Otra de las limitaciones que plantea recurrir a equipos pequeños pero potentes es que pueden limitar el número de procesos que se puedan ejecutarse en paralelo. En ocasiones podría resultar interesante ejecutar más de un proceso simultáneamente, aun cuando la ejecución se ralentice hasta cierto punto.
Transferir el volumen de datos que recopilan los sistemas modernos hasta los equipos dedicados puede resultar problemático. En ese sentido, una opción a tener en cuenta sería ubicar los equipos de procesamiento cerca de los datos. Esta es la estrategia que se sigue en los sistemas Spark y otros similares. En la actualidad, Spark carece de bibliotecas de aprendizaje automático de calidad.
Otro de los puntos en contra del uso de equipos dedicados tiene que ver con la flexibilidad. Los equipos de uso general pueden dedicarse a otras tareas en lugar de permanecer ociosos cuando no existen necesidades de entrenamiento.
Para alcanzar un nivel de flexibilidad máximo sin dejar de cumplir ninguno de los principios de computación distribuida, los equipos deben organizarse en contenedores (docker, rkt).
Estas consideraciones preliminares plantean la necesidad de dedicar cierto tiempo a evaluar si la idea de utilizar redes neuronales distribuidas es viable. Este artículo se centra en un marco de Aprendizaje Automático que ofrezce esta capacidad: Tensorflow de Google.
El objetivo del proyecto es desarrollar una arquitectura tan flexible como sea posible, capaz de ejecutar diferentes tipos de modelo para resolver diferentes tipos de problemas. Por lo tanto, estos sistemas han de ser tan independientes de los datos como sea posible.
En la medida de lo posible y por motivos de flexibilidad, el sistema no debería almacenar datos localmente. Este planteamiento contrasta con la tendencia actual de mover el código cuanto tan cerca de las fuentes datos como sea posible. Pero existen casos donde esto podría no ser la mejor opción, como, por ejemplo, cuando los datos se transmiten mediante streaming. Las operaciones bancarias o los eventos de negocio se transmiten por streaming. Esta configuración puede ser útil para desarrollar sistemas que estén aprendiendo ininterrumpidamente de un flujo (stream) constante de eventos.
La posibilidad de disponer de un sistema de aprendizaje automático en tiempo real a partir de un flujo de eventos en directo, capaz de modificar su escala para ajustarla a las variaciones de carga de dichos eventos, plantea un reto tan atractivo como complicado, que merece la pena explorar.
La posibilidad de disponer de un sistema de aprendizaje automático en tiempo real a partir de un stream, capaz de modificar su escala en función de la carga plantea un reto que merece la pena explorar
Arquitectura
A continuación se describe la arquitectura probada, basada en el framework Tensorflow, si bien otros marcos modernos dan respuesta a la mayoría de conceptos que planteamos. En general, todos los marcos siguen enfoques similares.
El ingeniero de datos define un modelo (algoritmo) para resolver un problema de aprendizaje automático. El modelo puede programarse en distintos idiomas. Los más populares en la actualidad son Python y R. Aunque Python es fácil de aprender y R está optimizado para el procesamiento de datos, no son los mejores en términos de rendimiento. Los marcos generalmente compilan el código fuente en una abstracción matemática, generalmente un gráfico que se compila posteriormente utilizando un lenguaje de menor nivel capaz de obtener un mejor rendimiento. Se utilizan bibliotecas altamente optimizadas, a veces específicas para cada tipo de hardware.
La siguiente imagen es una representación de la red neuronal modelada como un gráfico. El pantallazo está tomado de Tensorboard, una herramienta incluida en la distribución de Tensorflow que ayuda a diagnosticar problemas en un modelo.
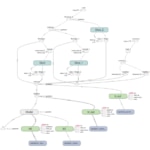
La representación gráfica de las operaciones permite, por ejemplo, calcular fácilmente derivadas.
Cómo dividir una red neuronal
Existen dos maneras de dividir la carga de una red neuronal entre diferentes máquinas:
- Paralelismo red / modelo. Las redes neuronales actuales están compuestas de una gran cantidad de capas. Cada capa requiere un grupo de computaciones que suelen representarse como un gráfico. Los datos circulan a través de los nodos de cálculo del gráfico en tensores, que no son otra cosa que matrices multidimensionales. Por ejemplo, una imagen puede estar compuesta de 4 canales de color (R, G, B, A), cada una de ellas siendo una matriz de dos dimensiones (3 dimensiones). Si la información de entrada es un vídeo, tendríamos una nueva dimensión, tiempo. Si, por motivos de rendimiento, pasamos más de una muestra en un lote añadimos otra dimensión.
Según este modelo, cada instancia de computación puede ubicarse en un dispositivo distinto. Este dispositivo puede ser un una unidad de procesamiento central (CPU) o gráfico (GPU), en la misma máquina o en una diferente. De esta manera sería posible sacar el máximo partido de cada dispositivo disponible pero hace necesario desarrollar cuidadosamente y asignar cada operación a un dispositivo específico. Esto quiere decir que es necesario conocer de antemano el equipo sobre el que se va a ejecutar el modelo. Este diseño, que puede funcionar en un laboratorio, podría no hacerlo correctamente en un entorno industrial o de negocios.
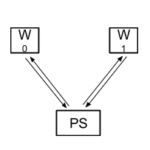
- Paralelismo de datos. El modelo en su conjunto se ejecuta en un equipo. Varias máquinas ejecutan el modelo en su totalidad, con diferentes rangos de datos. Cada uno de los equipos que ejecutan el modelo sería un nodo de trabajo (W o worker). Tras un determinado intervalo de tiempo (normalmente tras un lote) las diferentes instancias del modelo comparten parámetros y los reconcilian antes de continuar con el entrenamiento. Envían la información sobre los parámetros a un conjunto de equipos – servidores de parámetros (PS – parameter servers) que combinan los resultados y los devuelven a los nodos de trabajo.
Esta estrategia resuelve el problema que plantea la necesidad de conocer la configuración de los equipos por adelantado. De hecho, ésta puede cambiarse en cualquier momento. Esto supone una ventaja desde el punto de vista de la capacidad de recuperación. También puede ser muy importante en el caso de procesos de computación largos. Igualmente, ofrece un grado de flexibilidad óptimo, en el sentido de que podría permitir incrementar o reducir el número de máquinas (capacidad de computación) para ejecutar más tareas. Pero este modelo también exige una mayor inversión, puesto que requiere nuevos equipos que actuarían como servidores de parámetros, encargados de recopilar y combinar parámetros.
El proceso de reconciliación puede ser síncrono o asíncrono. Ambos ofrecen ventajas y desventajas. El proceso asíncrono tiene mayor capacidad de recuperación y permite el uso de equipos de diferente potencia de procesamiento, pero implicaría perder parte del tiempo de computación. El modelo síncrono, por otro lado, da mejor resultado cuando los equipos disponen de la misma potencia de procesado y están ubicados cerca de la red de comunicación. Pero es más sensible a cualquier problema en los nodos de trabajo. También codificación adicional para efectuar la sincronización.
Entorno
Para evaluar el paralelismo de datos se ha implementado el siguiente entorno. En el presente documento no se describen todos los elementos, sólo aquellos que afectan al rendimiento.
- Datos: Conforme a lo explicado anteriormente, los datos no se almacenan en los equipos de procesamiento, sino que se transfieren a ellos. De esta manera se simula un escenario probable en el que se recibirían los datos en streaming. De cara a efectuar las pruebas, los datos pueden almacenarse en archivos en máquinas específicas (no dedicadas al procesamiento) o generarse mediante una red de bots, que simule el comportamiento de los clientes.
Esta configuración simplifica el reparto de los datos entre un número variable de nodos de procesamiento. Esta no es, por supuesto, la forma más rápida de procesar datos en un entorno de aprendizaje automático.
Esta tarea se realiza utilizando un clúster de kafka. La red de bots publica los eventos sobre un tema y los nodos de procesamiento que actúan como consumidores los leen y los utilizan como vector de entrada para la red neuronal. - Procesamiento: Para entrenar la red neuronal de una manera distribuida utilizando Tensorflow hace falta utilizar dos tipos de nodos. El trabajo en sí es realizado por los nodos de trabajo. También hay un conjunto de nodos (servidores de parámetros) que recibe las diferentes versiones de los parámetros generados por los nodos de trabajo y los reconcilian antes de enviarlos de vuelta a los nodos de trabajo. La reconciliación de parámetros se realiza en modo asíncrono.
Todos los elementos se implementan como contenedores gestionados mediante Rancher. Cada ejecución con diferentes configuraciones se implementa en un ‘stack’ o pila. El uso de Rancher permite desplegar sistemas híbridos donde parte de sus nodos se implementa en una nube diferente.
Factores clave en términos de escalabilidad
El objetivo principal es conocer los límites en términos de escalabilidad. Es decir, determinar cuándo la incorporación de más nodos de procesamiento no se traduce en una reducción proporcional del tiempo. La manera de determinar esto es mediante un conjunto de ejecuciones de entrenamiento con los mismos datos, pero bajo diferentes configuraciones, que difieren, principalmente, en el número de nodos. Una vez que se alcanza un límite, se modifican otros parámetros de infraestructura para ver cómo dichos cambios afectan al rendimiento.
Topología de red neuronal
Tanto la topología de la red, como el número de capas y su tamaño tienen un impacto determinante en el rendimiento. Si toda la red debe calcularse en el mismo nodo de trabajo con paralelismo de datos, es importante asegurarse de que quepa en una sola máquina. En el caso de redes muy grandes es probable que esta no sea la mejor solución.
Tamaño del lote de entrenamiento
Como se ha explicado anteriormente, en la paralelización de datos, diferentes nodos de trabajo entrenan utilizando diferentes partes de los datos. Con una determinada frecuencia, es importante que se reconcilien los parámetros de red (combinados por media) para garantizar que todos convergen a la misma solución. Esto suele producirse tras una serie de lotes de entrenamiento.
Si el tamaño del lote es excesivo, los diferentes nodos se alejarán de la media y cuando se produzca la combinación se moverán hacia atrás. Se habrá desperdiciado parte del tiempo consumido. Por el contrario, si el número es demasiado pequeño, las combinaciones serán más frecuentes y se dedicará más tiempo al proceso de fusión y comunicación.
Los siguientes gráficos ilustran este efecto. Representan el mismo experimento con 4 nodos de trabajo y 2 servidores de parámetros. La única diferencia radica en el tamaño de los lotes (50, 100, 500 y 1000). Para garantizar que las redes no permanecen inactivas a la espera de los datos, la red de bots acelera su funcionamiento. Eso significa que el tamaño del lote incrementa notablemente el consumo de datos y de potencia de cálculo cuando el lote es más grande. Pero no mejora el tiempo final que se tarda en alcanzar la máxima precisión. Las ponderaciones en cada nodo varían tanto entre nodos que para cuando el promedio se calcula, se ha perdido demasiado tiempo. Y calcular el modelo requiere más tiempo.

Distribución de datos
Es importante asegurarse de que los datos se mezclan adecuadamente. De lo contrario podría ocurrir que ciertos nodos de trabajo reciban sólo cierto tipo de datos, de manera que el entrenamiento de éstos se vea modificado constantemente en función del aprendizaje en otros nodos.
Entradas de datos
El ancho de banda de la red de entrada (gestionado mediante kafka en nuestro caso) puede suponer una limitación si hay demasiados nodos de trabajo o si el vector de entrada es demasiado grande. Cuanto mayor el número de nodos de trabajo, mayor el volumen de datos que debe ser transferido a través de la red para mantenerlos ocupados a todos, lo cual supone un factor limitante en el rendimiento final del modelo. Una manera de superar este problema es cargar los datos en los nodos de trabajo de manera anticipada. Pero esa no es la arquitectura propuesta en este caso.
El cuello de botella puede ser tener su origen en el ancho de banda de la propia red o de cualquier componente involucrado en la distribución de datos.
Distribución variable a través de los servidores de parámetros
Conforme a lo expuesto anteriormente, la coordinación de los parámetros de red en forma de variables de Tensorflow se realiza mediante servidores de parámetros (PS). Cada variable se asigna a un servidor. Todos los nodos de trabajo se comunicarán con ese servidor periódicamente para fusionar el valor de la variable con el resto. Esto significa que, en el momento del arranque, todas las variables deberán asignarse a un PS específico y que todos los nodos de trabajo deberán estar al tanto de dicha asignación. Esta asignación podrá efectuarse manualmente por el programador del modelo o automáticamente por el configurador de dispositivos proporcionado por el marco.
La asignación manual, probablemente, ofrecerá un mejor rendimiento, pero puede hacerse sabiendo de antemano el hardware involucrado. El objetivo de este trabajo es estudiar cómo ejecutar las redes neuronales de una manera flexible, de manera que la asignación manual carecería de sentido.
El configurador de dispositivos hasta la versión 0.11 realizaba esta tarea utilizando una estrategia round-robin. El programador debe ser consciente de esto para evitar que se produzcan ciclos donde todas las variables "pesadas" recaigan sobre el mismo PS, situación que puede suceder con mayor frecuencia de lo que podría pensarse.
Por ejemplo: Durante el desarrollo de una red neuronal profunda se han de crear varias capas. Si estas capas son capas completamente conectadas tendrán dos variables, el peso y el sesgo. La primera será al menos una matriz bidimensional y el sesgo tendrá una dimensión menos, por haciéndola quizás mil veces menor que los pesos. Una manera natural de crear esto es mediante bucle. Cada barrido creará una capa, creando las variables secuencialmente, empezando por el peso y después el sesgo. En caso de que sólo haya dos PS, la planificación round-robin asignará todos los pesos al mismo PS y los sesgos al otro.
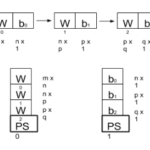
Este problema se puede resolver fácilmente agregando otro PS, pero el operador de ser consciente de ello todo el tiempo. En la versión 0.11 el configurador de dispositivos acepta una función de estrategia como parámetro. La función conoce los dispositivos, servidores de parámetros. Cada vez que se crea una nueva variable se lanza una llamada a esta función y devuelve el dispositivo al que debe ser asignada. A partir de la versión 0.12 se proporcionan dos estrategias, la primera es round-robin que es la que viene seleccionada de predeterminada. El segundo es una estrategia codiciosa, cuyo objetivo es difundirlas a través del PS en función del tamaño en bytes. La estrategia debe ser codiciosa, ya que no conoce las variables de antemano. Si la red dispone de muchas variables pequeñas con posibilidades de terminar todas ellas en el mismo PS, podría incrementar la presión sobre el mismo hasta el punto de causar un cuello de botella.
Las siguiente imagen muestra cómo Tensorboard (la herramienta de depuración de Tensorflow) muestra la ubicación de las variables en los dispositivos. Se puede ver que h0, h1 y h2, las variables que almacenan los pesos de la matriz, se almacenan en el mismo servidor de parámetros. Esto puede convertir el servidor de parámetros /job/ps/task:0 en un cuello de botella.
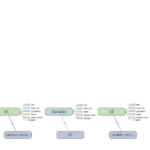
Número de nodos de trabajo
Esta es la variable más obvia. El sistema no puede escalarse hasta el infinito. Si existe un número elevado de nodos de trabajo, éstos deberán mantenerse alimentados con datos de entrada y se deberán enviar las variables a los servidores de parámetros.
Conforme se añaden más nodos de trabajo el tiempo total de entrenamiento va disminuyendo, hasta llegar a un punto a partir del cual no se observa mejoría alguna. Una manera mejor de medir esto es controlando el tiempo agregado de computación que mide el coste total. Mientras permanezca sin cambios, la incorporación de nodos de trabajo sigue siendo rentable.
Cada modelo tiene un punto óptimo. Pero este punto no es el mismo en todos los casos. Durante las pruebas algunos modelos llegaron este punto con 7 y otros con 20. Pero en modelos complejos (millones de parámetros debido a imágenes muy grandes, por ejemplo), el número puede ser mucho mayor.
Número de servidores de parámetros
Tal y como hemos visto, las variables que contienen los parámetros de red se almacenan en los servidores de parámetros. Si el número de servidores de parámetros no es lo suficientemente elevado, la carga que soporten puede llegar a ser demasiado alta. En las pruebas ejecutadas, estos servidores terminan empleando todo su ancho de banda de la red. El límite superior inicial parece ser un servidor de parámetros por variable, pero esta opción no sería rentable.
Se han identificado dos maneras de manejar esta limitación que están pendientes de probarse. Si la ejecución se realiza en una nube, no sería mala idea usar máquinas con el mayor ancho de banda disponible. La documentación de Tensorflow indica que las variables pueden ser divididas y almacenadas en diferentes servidores de parámetros, una opción a la que se podría recurrir en el caso de una variable muy grande, de cara a distribuir la carga entre los servidores de parámetros.
Es importante tener en cuenta que todos los nodos de trabajo (workers) deben comunicarse con todos los servidores de parámetros cada ciclo de combinación.
También hemos averiguado que los dos primeros servidores de parámetros (0 y 1) también almacenan variables relacionadas con el guardado de la sesión. Esto, por supuesto, repercute sobre el ancho de banda de red consumido por ellos. Podría merecer la pena intentar una estrategia que almacene variables en otros servidores de parámetros diferentes que no sean 0 y 1.
Topología de la red de comunicaciones
Como hemos explicado en puntos anteriores, las comunicaciones en general pueden convertirse en un cuello de botella importante y deben revisarse cuidadosamente. Como se ha dicho, es importante asegurarse de que los servidores de parámetros tengan la mejor conectividad de red, ya que recibirán información de todos los nodos de trabajo.
El modelo distribuido es, en términos generales, especialmente atractivo para entornos en la nube. El tipo de máquina es importante, la afinidad de los recipientes debe ser establecida cuidadosamente.
Conclusiones
Las redes neurales distribuidas no pueden ser escaladas al infinito. A pesar de que Google afirma que pueden escalarse hasta los miles de nodo, esta opción requeriría de un diseño muy cuidadoso, que no es óptimo para un uso genérico.
Las redes neuronales distribuidas no pueden ser escaladas al infinito.
Cada elemento plantea diferentes necesidades en términos de red y potencia de procesamiento. Si se va a definir un entorno de nube, podría ser buena idea recurrir a diferentes tipos de hosts de hardware. Los nodos de trabajo, o workers, necesitan principalmente potencia de procesamiento y probablemente RAM, y si disponen de GPUs su rendimiento podría mejorar notablemente. Pero es importante que todos los nodos tengan características similares. En el caso de los servidores de parámetros, la potencia de procesamiento no es tan importante, pero el ancho de banda de la red es crítico.
En el caso de entornos híbridos de nube o nubes con varias ubicaciones, es importante asegurarse de que los nodos de trabajo y los servidores de parámetros no estén demasiado lejos.
El uso de nodos con GPUs dedicadas aumenta el rendimiento en gran medida, pero viene con el coste de desarrollo específico. Desde el punto de vista de Tensorflow se trata únicamente de configurar el dispositivo. Pero en un entorno distribuido, el hardware debería conocerse perfectamente de antemano o debería incluirse algún código específico en el modelo para detectar el hardware disponible. Incluso esto puede plantear problemas, porque los nodos más lentos pueden reducir el rendimiento y sus cálculos pueden ser ignorados completamente.
Una limitación importante en Tensorflow está relacionada con la escalabilidad. En el momento del arranque, todos los nodos deben conocer las direcciones y puertos de todos los nodos de la red. Esto implica que no podría escalar el sistema sobre la marcha. Sí que se podría reducir su escala. En caso de que hubiera problemas con algún nodo de trabajo, la red seguiría funcionando bien. Esto es bueno desde el punto de vista de la capacidad de recuperación. En caso de que hicieran falta más nodos, habría que parar el procesamiento, añadir los nuevos nodos y reiniciar la red. El trabajo realizado hasta la interrupción no se perdería si se guarda la sesión. Esta posibilidad existe en todos los marcos disponibles, incluido Tensorflow, pero el modelo tendría que programarse tomando esta posibilidad en consideración.
Durante una conversación, un ingeniero de Google aseguró que es posible agregar nodos de trabajo redundantes que permanecerían inactivos hasta que se produjera algún fallo en un nodo, manteniendo el rendimiento esperado en el caso del paralelismo de datos o evitando el error en el caso de un modelo dividido entre diferentes máquinas, pero no hemos verificado esta afirmación.
Te animamos a participar enviando tus comentarios a BBVA-Labs@bbva.com y, si eres de BBVA, aportando tus propuestas de publicación.