El paradigma de la ‘edge computing’
La ‘edge computing’ es un modelo en el que los datos, el tratamiento informático y las aplicaciones se concentran en los propios dispositivos de la red en lugar de existir casi solo en la nube.

La ‘edge computing’ es un paradigma que amplía la nube a las ubicaciones de la red. Al igual que la nube, la ‘edge’ (‘frontera’) ofrece a los usuarios finales servicios de datos, computación, almacenamiento y aplicaciones.
La ‘edge computing’ reduce la latencia del servicio y mejora su calidad, lo que para el usuario se traduce en una experiencia mejor. Este paradigma es compatible con el concepto emergente de aplicaciones ‘metaverse’, que exigen una latencia de tiempo real y predecible (automatización industrial, transportes, redes de sensores y conmutadores). Además, el paradigma de ‘edge computing’ tiene gran potencial de cara al Big Data y la analítica en tiempo real, ya que permite puntos de recogida de datos de distribución densa, añadiendo así un cuarto eje a las tres dimensiones existentes del Big Data (volumen, variedad y velocidad).
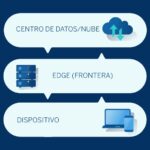
A diferencia de los centros de datos tradicionales, los dispositivos ‘edge’ se distribuyen geográficamente entre plataformas heterogéneas y abarcan entornos de gestión diversos. De este modo, los datos no necesitan ser enviados a la nube para su tratamiento, sino que se tratan de forma local en los propios dispositivos inteligentes.
Los servicios de ‘edge computing’ incluyen:
- Aplicaciones que exigen una latencia muy baja y predecible
- Aplicaciones distribuidas geográficamente
- Aplicaciones móviles de ejecución rápida
- Sistemas de control distribuido a gran escala
Ventajas de la ‘edge computing’
- Acercar los datos al usuario. En lugar de almacenar datos en centros alejados del punto de destino, el paradigma edge los sitúa cerca del usuario.
- Crear una distribución geográfica densa. El Big Data y la analítica se realizan más rápido y con mejores resultados. Además, el administrador puede atender solicitudes de movilidad por ubicaciones concretas, sin tener que recorrer toda la red. Por último, el diseño de los sistemas ‘edge’ permite analítica de datos en tiempo real a gran escala.
- Soporte real a la movilidad y al metaverso. Al gestionar datos en distintos puntos, la ‘edge computing’ integra los servicios básicos de la nube con los de una plataforma de centro de datos distribuida en términos físicos y reales. A medida que surjan más servicios para el usuario final, las redes ‘edge’ se irán ampliando.
- Numerosos verticales se muestran receptivos. Muchas entidades ya se interesan por el concepto ‘edge computing’. Ya existen distintos servicios diseñados para ofrecer al usuario final una mayor riqueza de contenidos, ofrecidos por proveedores de informática o empresas de ocio y entretenimiento, entre otros.
- Integración sin fisuras con la nube y otros servicios. Mediante servicios ‘edge’, se mejora la experiencia en la nube aislando aquellos datos del usuario que deben ubicarse en la ‘frontera’. A partir de ahí, el administrador puede incorporar analítica de datos, seguridad u otros servicios directamente a su modelo de nube.
Otras ventajas de la ‘edge computing’
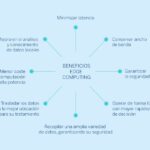
- Minimizar latencia
- Conservar ancho de banda
- Abordar cuestiones de seguridad a todos los niveles de la red
- Operar de forma fiable con mayor rapidez de decisión
- Recopilar una amplia variedad de datos, garantizando su seguridad
- Trasladar los datos a la mejor ubicación para su tratamiento
- Ahorro de costes, al invocar cálculos de alta potencia solo cuando se necesitan y utilizar menos ancho de banda
- Mejora en el análisis y conocimiento de datos locales
Ejemplo real:
En una gran ciudad, los semáforos están dotados de sensores inteligentes. El equipo local acaba de ganar un campeonato y es el día del desfile para celebrarlo. Se prevé una oleada de tráfico hacia el centro de la ciudad cuando los hinchas acudan a celebrar la victoria. A medida que aumenta el tráfico, se recogen datos de todos los semáforos. La aplicación desarrollada por el ayuntamiento para ajustar la pauta de apertura y cierre de cada semáforo se ejecuta directamente en cada dispositivo de ‘frontera’. Así, en la frontera de la red, la aplicación ajusta de forma automática y en tiempo real las pautas de apertura y cierre, en función del tráfico y a medida que aumenta o disminuye. Los atascos se reducen al mínimo. Los aficionados pasan menos tiempo en el coche, por lo que tienen más tiempo para celebrar la victoria.
Una vez finalizado el evento, todos los datos extraídos del sistema de semáforos se envían a la nube para su análisis predictivo, lo que permite al ayuntamiento mejorar la respuesta de su aplicación de tráfico a otras situaciones atípicas como esta. No tendría mucho sentido enviar a la nube para su almacenamiento y análisis un flujo constante y en directo de datos de sensores de tráfico. Los expertos en la materia ya conocen bien las pautas de tráfico normales. Los datos de sensor más relevantes son precisamente aquellos que se apartan de lo normal, como los que surgen en un día de celebración masiva.
Futuro de la ‘edge computing’
A medida que se introduzcan más servicios, datos y aplicaciones que se ubiquen y ejecuten directamente en el dispositivo del usuario final, los informáticos tendrán que optimizar cada vez más el proceso de entrega. Esto implica acercar la información al usuario, reducir la latencia y prepararse para el metaverso y sus aplicaciones de Web 3.0. Cada vez son más los usuarios que gestionan su trabajo y vida personal en un entorno de movilidad. La riqueza de contenidos y abundancia de puntos de datos están llevando a las plataformas de la nube, literalmente, al límite -es decir, ‘the edge’-, donde las necesidades de los usuarios no paran de crecer.
Con el aumento en la utilización de datos y servicios en la nube, la ‘edge computing’ tendrá un papel fundamental en reducir la latencia y mejorar la experiencia del usuario. Es ahora que por fin estamos distribuyendo realmente los datos y llevando los servicios avanzados a la ‘frontera’ de la red. De este modo, un administrador de red puede ofrecer al usuario una gran riqueza de contenidos de forma más rápida, eficaz y, sobre todo, más económica. En última instancia, esto supone mejoras en acceso a datos, en capacidad de analítica corporativa y en experiencia del usuario en su conjunto.
Al trasladar el tratamiento inteligente de datos a la frontera de la red, aumenta aún más la importancia de mantener la disponibilidad de las pasarelas inteligentes y sus vías de comunicación con la nube. El Internet de las Cosas (IoT) ya permite a las personas gestionar su vida diaria -cerrar con llave las puertas y ventanas de casa, vigilar citas y eventos en el calendario, incluso preparar comidas mediante robot-. Por ello, en el mundo de la ‘edge computing’, cualquier falta de disponibilidad de conexión supone un problema de crítica importancia, y las soluciones de resiliencia y de ‘failover’ o conmutación por error que protegen esos procesos serán aún más cruciales. Así, nos iremos alejando de las presiones del sistema centralizado que hasta ahora ha definido la infraestructura de Internet para llegar a un nuevo paradigma de distribución a ubicaciones locales.
Referencias
https://www.linkedin.com/pulse/why-iot-needs-fog-computing-ahmed-banafa/
https://www.linkedin.com/pulse/fog-computing-vital-successful-internet-things-iot-ahmed-banafa/
http://www.cisco.com/web/about/ac50/ac207/crc_new/university/RFP/rfp13078.html
http://www.howtogeek.com/185876/what-is-Edge-computing/
http://newsroom.cisco.com/feature-content?type=webcontent&articleId=1365576