La Economía de las Arquitecturas 'Serverless'
Nuestra meta inicial es intentar responder a preguntas tales como cuándo es más apropiado usar AWS Lambda en vez de los servicios AWS EC2 y, especialmente, qué parámetros tienen más impacto en esta comparación.

Introducción
En este trabajo examinamos el precio del servicio 'serverless' de Amazon Web Services (AWS), conocido como 'AWS Lambda'. Comparamos su estrategia de precios con la del servicio AWS Elastic Compute Cloud (EC2), examinando en detalle qué suposiciones han de hacerse para poder comparar ambos servicios.
Encontramos que, lejos de obtener respuestas blancas o negras a estas preguntas, una variedad de factores específicos a cada servicio pueden determinar cuál es la mejor elección, y discutimos y proveemos conclusiones para un número de casos de estudio relevantes.
Nuestro enfoque está basado en modelos teóricos e inspirado por simulaciones de servicios del mundo real típicos que nos dan una idea de qué variable es importante que consideremos en el modelo que usemos al planear el uso de estas tecnologías. De hecho, estos simuladores, que hemos publicado como 'Open Software', pueden ser de gran utilidad durante la fase de planificación de un servicio 'software', donde es clave determinar qué tecnologías apalancar para ahorrar tiempo y dinero.
Descubriremos que es esencial tener un conocimiento profundo de cómo tu aplicación funciona para poder ser capaz de optimizar sus costes, y asegurar que nuevas funcionalidades no los penalizan. También analizaremos la contribución de lo que hemos denominado «factor de rendimiento», que nos permite establecer una comparación entre ambas arquitecturas.
En esencia, una arquitectura 'serverless' (también conocida como Función-como-Servicio o FaaS, por sus siglas en inglés) provee capacidad de cómputo para ejecutar nuestro código de aplicación sin necesidad de provisionar ni gestionar servidores. El proveedor de 'cloud' ejecuta el código (llamado función) sólo cuando se necesita, y escala automáticamente para satisfacer la demanda.
En posts anteriores discutimos la arquitectura Serverless, así como los principales proveedores de 'cloud' que la ofrecen. Además, analizamos cómo desplegarla en tus instalaciones con 'Fission' y 'OpenShift' de 'RedHat'.
Las funciones desplegadas en este servicio (AWS Lambda) se benefician de la integración con otros servicios del proveedor de 'cloud'. Sin embargo, esto incrementa el llamado 'vendor lock-in', o dependencia en el proveedor, potencialmente haciendo impráctico el despliegue de nuestra aplicación en otras nubes. Merece la pena mencionar que sólo podemos ejecutar código en lenguajes de programación soportados por el proveedor.
Es claro, simplemente leyendo la descripción del servicio, que el proveedor de nube se ha centrado en diferentes casos de uso para cada plataforma: si o bien tu carga de trabajo no puede ser implementada en ninguno de los lenguajes soportados por AWS Lambda, o bien se trata de un ejecutable de terceros, o bien depende fuertemente de acceso a almacenamiento local, en esos casos una oferta de instancia 'cloud' (máquina virtual) de proveedores de 'cloud' pública tales como AWS, Google, IBM o Microsoft, parece la opción más adecuada. Sin embargo, hay una plétora de aplicaciones y cargas de trabajo que pueden correr en AWS que se pueden beneficiar de sus fortalezas; exploraremos algunas en esta obra.
En este estudio, nos centramos en AWS Lambda, ya que es una de las plataformas 'serverless' más utilizadas, y soporta múltiples lenguajes de programación, tales como Python, Java, Go, C# y Node.js.
La mayoría de los 'papers' que hemos encontrado sobre el asunto tienden a centrarse sólamente en los beneficios de no tener que reservar capacidad de cómputo de antemano, y su consiguiente ahorro económico. En nuestra opinión, un análisis en profundidad, considerando cargas de trabajo realistas, nos permitiría juzgar mejor el impacto que esta arquitectura tendría en nuestros costes.
Suposiciones de negocio
Para poder realizar simulaciones y estudiar en profundidad el impacto económico de la arquitectura 'serverless' (AWS Lambda) comparada con instancias de máquina virtual (AWS EC2), hemos de hacer algunas suposiciones relativas al modelado del negocio:
- Suponemos que el código de aplicación funciona sin cambios en ambos servicios EC2 y Lambda. Esto es necesario para poder realizar la comparación de dichos servicios. A menudo, el código heredado ('legacy') necesita ser transformado para ser usado en una plataforma 'serverless'. Las aplicaciones monolíticas, o 'software' que necesita acceder a las capas de bajo nivel del sistema operativo son malos candidatos para correr en una arquitectura 'serverless', a menos que nos embarquemos en una refactorización profunda del código. Además, el proveedor de 'cloud' puede restringir el acceso a algunos paquetes de 'software' que considere potencialmente peligrosos, limitando la compatibilidad de las funciones 'serverless' con código que fue diseñado para instancias 'cloud' ordinarias.
- Suponemos que nuestra aplicación es capaz de autoescalar las instancias 'cloud' (VMs) en servicio, aumentando su número a medida que las peticiones entrantes crecen más allá del límite de peticiones que una única instancia puede procesar.
- Notablemente, no tenemos en cuenta los ahorros derivados de no tener que administrar el entorno en la plataforma IaaS (AWS EC2). Seguramente, esta partida podría representar un punto de inflexión cuando los costes para ambos servicios están dentro del mismo orden de magnitud. Sin embargo, es casi imposible establecer una suposición razonable aquí, ya que los costes laborales varían ampliamente de un país a otro.
- En nuestras simulaciones hemos usado diferentes ratios de la cantidad de memoria necesaria para procesar una sola petición usando una arquitectura 'serverless' frente a una instancia 'cloud'. A menudo, usaremos un ratio de rendimiento de 1:1, queriendo decir esto que una instancia 'cloud' puede procesar tantas peticiones como quepan en su memoria total, usando la misma cantidad de memoria por petición que una función 'serverless'.
- Finalmente, suponemos que nuestra organización dispone de suficiente conocimiento para programar, configurar y desplegar arquitecturas serverless. Aunque las arquitecturas 'serverless' nos evitan tener que desplegar una infraestructura de servidores web, los equipos técnicos de muchas organizaciones no tendrían porqué tener necesariamente experiencia alguna desplegando aplicaciones de esta manera novedosa.
Casos de uso tratados en esta obra
Hemos identficado varios casos de uso que son suficientemente dispares entre sí como para ser tratados independientemente. La mayoría de los estudios que hemos encontrado sólo tienen encuenta como mucho el primer caso.
Ono de los argumentos de venta que los proveedores de 'serverless' a menudo resaltan es que las arquitecturas 'serverless' eliminan la necesidad de tener que cambiar el despliegue para poder acomodar un subida (posiblemente enorme) en la carga de trabajo.
¿Cómo afecta la distribución de peticiones a lo largo de un período de 24 horas al coste total? ¿Y la escala total de las peticiones? ¿Tiene impacto que la aplicación sea de consumo puramente local (como un servio metropolitano, por ejemplo) frente a uno global?
Profundizando el el asunto de la escalabilidad, no tener instancias 'cloud' corriendo 24/7 para responder a peticiones equiespaciadas en el tiempo (como en un caso de dispositivos IoT, por nombrar alguno) parece ser un buen caso de uso para 'serverless': sólo se incurrirán costes cuando una petición sea realizada. ¿Cómo se comportará el coste cuando el número de dispositivos aumenta? ¿Afecta la frecuencia de las peticiones a la comparación de costes?
Modelo de precios de instancias 'cloud y serverless'. Diferencias principales
La mayoría de los proveedores de nube cobran por el tiempo que una máquina virtual está corriendo, con un mínimo de 60 segundos. El precio depende de las características de la instancia (tales como el tipo de CPU, cantidad de RAM, disponibilidad y/o almacenamiento) y el compromiso realizado a priori para usar dichas instancias. La elección del tipo de instancia adecuado es muy dependiente de la aplicación.
La función que determina el coste mensual de una instancia Lambda depende de tres parámetros:
- El número de ejecuciones o peticiones (lo llamaremos n) en ese intervalo,
- La cantidad de memoria reservada por la instancia (m)
- El tiempo de ejecución estimado (d) en milisegundos.
Así, el coste total, Cλ , para una cantidad dada de peticiones n, puede ser expresada matemáticamente así:
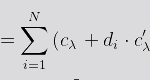
donde:
- Cλ es la función de coste para un número dado de peticiones.
- cλ es el coste fijo por petición.
- di es la duración de la función (en ms)
- c'λ es el coste por segundo para la función 'serverless'.
- N es el número total de peticiones en un período dado.
Por otra parte, la función de coste de una instancia EC2 depende, a su vez, del tiempo que está en ejecución así como del máximo número de peticiones por segundo que puede gestionar (rmax).
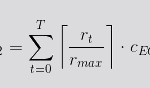
- CEC2 es la función de coste de EC2 sobre un período dado T.
- rt es el número de peticiones a procesar en un segundo.
- rmax es el máximo número de peticiones que una instancia puede procesar en un segundo.
- cEC2 es el coste por unidad de tiempo (segundos) para una instancia 'cloud' dada.
- T es el período de tiempo para el análisis de coste.
Comparando el despempeño de 'serverless' e instancias 'cloud'
Hemos producido un modelo teórico que intenta relacionar el desempeño de las instancias 'cloud' y las funciones 'serverless' usando el número máximo de peticiones por segundo como el parámetro que las une. Así, podemos expresar el máximo número de peticiones por segundo que una instancia 'cloud' puede gestionar en relación con la memoria y tiempo de ejecución en una función 'serverless' de esta manera:
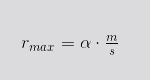
donde:
- rmax es la cantidad máxima de peticiones por unidad de tiempo que una instancia 'cloud' puede procesar.
- m es la cantidad de memoria, en MiB, de la instancia 'cloud'.
- s es la cantidad de memoria del sabor de 'serverless', en MiB.
- α es la constante del ratio de rendimiento.
Introducimos α en la ecuación para tener en cuenta la posible diferencia de desempeño entre ambas arquitecturas. Al igual que otros parámetros ya discutidos anteriormente en este artículo, es muy dependiente de la aplicación, y ha de ser estimado caso a caso, midiendo el impacto específico de las siguientes contribuciones:
- Huella de memoria del sistema operativo en el caso de instancias 'cloud'
- Sobrecarga de memoria inherente a instanciar funciones aisladas para procesar cada petición (en el caso de 'serverless'), en contraposición a tener una única instancia 'cloud' compartiendo sus recursos entre múltiples llamadas a función.
- En una función limitada por CPU, el tiempo de ejecución será afectado drásticamente por el sabor de Lambda elegido. Por otro lado, una función limitada por I/O no se verá afectada en demasía por un sabor de Lambda con bajo desempeño de CPU.
Podemos definir ratio de rendimiento como la relación cuantitativa entre la memoria consumida por una función 'serverless', frente a la misma función ejecutada como código ordinario en una instancia 'cloud'. Hay algunos aspectos que lo hacen crecer, como el peor desempeño de las CPUs disponibles en Lambda comparado con las disponibles en EC2. Sin embargo, hay otros que lo reducen, tal como la huella de memoria del sistema operativo de la instancia 'cloud'.
El siguiente gráfico muestra el coste mensual frente al número de peticiones por segundo, para tres ratios de rendimiento α: 1, 5 y 10.



Suposiciones técnicas
Para poder ser capaz de comparar los precios de las instancias 'cloud' y 'serverless', necesitamos suponer que:
- Los servicios comunes usados por ambas arquitecturas no están tratadas aquí, ya que afectan a ambas de la misma manera. En concreto: costes del 'API gateway', transferencia de datos, almacenamiento y otros servicios 'cloud' no se considerado explícitamente para el alcance de este estudio.
- Para replicar la alta disponibilidad de los servicios 'serverless', nuestro servicio necesitará un mínimo de una instancia corriendo en todo momento, independientemente de su uso. Esta es la razón por la que en este estudio no hemos considerado ningún tipo de instancia con pre-reserva ('spot/preemptible/reserved').
- Para acomodar los picos de demanda, nuestro servicio escalará horizontalmente cuando se supere el umbral predefinido de peticiones por segundo: cuanto más potente es la instancia, mayor es el número de peticiones por segundo que puede gestionar. De esta manera, en este estudio no hemos considerado situaciones de escalado vertical, donde el tipo de instancia se cambia dependiendo de el crecimiento esperado de la carga.
- Nuestro servicio no es adecuado para tareas de procesado fuera de linea o por lotes: las petitiones han de ser procesadas al llegar tan rápido como sea posible.
Hemos tomado los precios de AWS EC2 service pricing y AWS Lambda pricing para el estudio, con fecha de febrero de 2018.
Modelo de aplicación y parámetros
Para poder modelar una aplicación en ambas arquitecturas, necesitamos identificar los valores de los siguientes parámetros:
- Peticiones totales en el período estudiado.
- Duración de una petición, en milisegundos.
- Consumo de memoria de cada petición.
- Distribución de las peticiones en el tiempo. Aunque no afecta a la arquitectura 'serverless', impacta directamente la capacidad de cómputo comprometida a lo largo del tiempo en le caso de instancias 'cloud'.
Aunque los parámetros son los mismos para ambas arquitecturas, sus valores numéricos probablemente no coincidan para un servicio dado:
- La cantidad total de memoria requerida para procesar una sola petición en una arquitectura 'serverless' es mayor que en una instancia 'cloud'. Un servicio 'serverless' necesita crear el entorno de ejecución, y su huella de memoria será a menudo mucho mayor en esta arquitectura. Por esta razón, no podemos simplemente dividir la cantidad de memoria RAM de una instancia entre la cantidad de memoria de la Lambda: esto no sería justo para las instancias 'cloud'. Como hemos mencionado previamente, usaremos el ratio de rendimiento (α) para ajustar esta relación entre ambas arquitecturas.
- Por contraposición, hemos considerado que el tiempo de ejecución es igual en ambas arquitecturas. Sin embargo, conviene mencionar que proveedores como AWS asignan el doble de potencia de CPU cuando el 'sabor de serverless' dobla su cantidad de memoria. Este no es el caso con Google Cloud Platform, donde se ofrecen sabores con múltiples combinaciones de memoria y potencia de cómputo.
Por consiguiente, cuando decidamos qué sabor de 'serverless' usar en AWS Lambda, el sabor (definido en términos de memoria únicamente) afectará el tiempo que la función Lambda necesitará para procesar una petición, si es intensa en CPU (por contraposición a intensa en memoria o E/S).
Basándonos en estas premisas, ¿cómo seleccionaremos el sabor de 'serverless' en AWS Lambda?
- Hemos de seleccionar el sabor Lambda más pequeño que sea capaz de correr nuestro código, y después
- Seleccionar un sabor Lambda que sea capaz de alcanzar el nivel de servicio deseado (peticiones por segundo) consistentemente:
- Hemos de saber si nuestro código está limitado por CPU o por E/S:
- Si está limitado por CPU: usaremos el sabor Lambda más potente disponible → esto asegurará el mejor nivel de servicio al mismo precio
- Si está limitado por E/S, usaremos el sabor Lambda más pequeño disponible → esto nos dará un nivel de servicio aceptable con el mínimo coste.
Recomendamos la medición de estos límites en nuestro código. Así, seremos capaces de adaptar nuestra aplicación para optimizar el precio, y asegurarnos de que las nuevas funcionalidades o cambios que introduzcamos no penalicen los costes. Ésta es una baza increíblemente importante al construir aplicaciones: conocer a priori el impacto de cada cambio en el coste.
Simulaciones
En BBVA-Labs, nos preguntamos cómo haríamos un 'benchmarking' de costes que contemplara tantos casos como fuera posible. Queríamos producir un entorno que, aunque siendo genérico, a la vez aplicara al mayor rango posible de casos.
Con eso en mente, elegimos un entorno de simulacion donde múltiples parámetros pudieran ser afinados para ajustarse mejor a un caso específico. Decidimos elegir jupyter notebooks con Python 3.6 junto con las bibliotecas pandas and NumPy como nuestro entorno de trabajo. Junto a los 'notebooks', hemos producido un puñado de paquetes Python que encapsulan los detalles más escabrosos de la contabilidad de costes y la simulación.
Usaremos tres de los tipos de instancia más comúnmente empleados para proporcionar una buena visión de conjunto de la evolución de la comparacion de precios.
Con todo ello en mente, proponemos simular varios casos de uso, haciendo diferentes suposiciones para ver cómo éstas impactan en el modelo, indentificando cuales son las variables más importantes para diseñar el servicio.
El código fuente de los 'notebooks' y los paquetes Python puede descargarse desde nuestro repositorio público de BBVA en GitHub.
Caso 1: Tasa de peticiones uniforme durante un mes entero (caso irreal)
Escenario
Este caso consiste en una simulación de peticiones distribuídas uniformemente durante un marco temporal de un mes de duración. Analizamos cómo el coste aumenta dependiendo de la tasa a la que las peticiones son procesadas por un servicio dado.
Al disponer de una distribución de peticiones, somos capaces de calcular costes por el uso de instancias de EC2 y AWS lambda, una vez que establecemos la tasa máxima (peticiones por segundo) que cada sabor de EC2 es capaz de procesar antes de tener que escalar horizontalmente una nueva instancia. En vez de usar valores arbitrarios para cada sabor de EC2, podemos usar el ratio de rendimiento α que discutimos en el capítulo 1.4. En efecto, los gráficos de aquel análisis son válidos aquí, ya que entonces empleamos también una distribución uniforme de peticiones a lo largo de un mes para obtenerlos.
Lo mismo aplica al sabor de Lambda: ¿qué tamaño de memoria y tiempo de ejecución debemos elegir?
Para este estudio concreto, elegimos 128MiB, y un tiempo de petición de 200ms. Se pueden usar varios valores, pero por simplicidad usaremos valores fijos para la duración de la petición (di) y memoria. Variaciones en ellos causarán que las curvas de coste suban de cota, pero la forma y pendiente de estas curvas se mantendrá inalterada.
Animamos al lector a que clone nuestro repositorio, y a juguetear con los 'notebooks' para afinarlos y hacer así que se ajusten a los requisitos específicos a su servicio.
La mayoría de los estudios acaban su análisis económico aquí. Pero en el mundo real las peticiones no llegan de una manera uniforme y organizada, y nos preguntamos si esto podría afectar al aspecto económico.
Caso 2: Un modelo más humanizado
Aunque el estudio anterior nos ayuda a tener una idea aproximada de cómo la escala de la demanda afecta al coste, el escenario donde un número constante de peticiones por segundo se mantiene durante un mes entero es ciertamente inverosímil.
Escenario
Queríamos construir un escenario más anclado en la realidad, simular el tráfico producido por una base de usuarios globalmente distribuídos, teniendo en consideración zonas horarias y hábitos. Para hacerlo, creamos un modelo basado en datos de tráfico históricos (visitas) del sitio de la Wikipedia para dar forma a la distribución de peticiones. Posteriormente, aplicamos un factor de escala para hacerlo crecer hasta el número deseado de visitas totales al mes.
Una semana cualquiera de la Wikipedia en inglés tiene este aspecto:
Dado que la serie histórica parece presentar una fuerte temporalidad semanal, procedimos a colapsar todas las peticiones a la Wikipedia durante un año entero en una única semana promedio. Entonces construímos un mes sintético de peticiones a la Wikipedia, con un total de 100 millones de peticiones, y lo normalizamos.
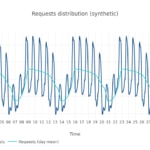
Basándonos en esta distribución de peticiones, podemos ahora proceder a calcular los costes asociados a la instancia EC2 y a la Lambda empleados.
Según las suposiciones relativas a las características de servicio (huella de memoria, tiempo de ejecución, etc.), podemos estudiar cómo se desarrollan los costes en una infraestructura 'serverless' frente a una más tradicional, basada en instancias 'cloud'.

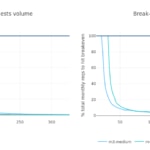
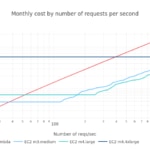
Pero, ¿cómo evolucionan estos valores con el total de peticiones mensuales (esto es, la escala)? Analizamos el momento en el que se alcanza la paridad en coste durante el mes frente a la cantidad total de peticiones mensuales. Para facilitar la lectura, usamos el número medio de peticiones por segundo al mes:
Usando el último gráfico podemos dar una estimación visual de cuánto más cara sería una architectura Lambda si empezamos a recivir más peticiones de las que esperábamos en un cierto mes.
Ideas
De los gráficos anteriores cabe resaltar:
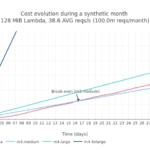
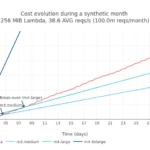
- El primer punto de paridad de coste se alcanza al llegar aproximadamente a las 90 millones de peticiones mensuales (~35 peticiones por segundo de media) con una Lambda de 128MiB. Usando una Lambda de 256MiB este punto sube a 52 millones de peticiones mensuales (~20 peticiones por segundo de media).
- Una vez que el punto de paridad de coste se alcanza para unos sabores de Lambda y EC2 dados, se mueve rápidamente, haciendo el uso de Lambda mucho más caro que una instancia de EC2. Este punto de inflexión es muy sensible al aumento de unos pocos miles de peticiones mensuales.
- El punto de paridad de coste donde las instancias de EC2 empiezan a ser más económicas que Lambda se alcanza simplemente on una instancia, sin necesidad de escalar horizontalmente el número de instancias 'cloud'. De esta manera, la contribución del factor de rendimiento es irrelevante en este caso.
La lección aprendida aquí es cuán rápidamente los beneficios de coste de tener una arquitectura 'serverless' se evaporan una vez que el coste de nuestro servicio sobrepasa el punto de paridad en coste. Sin embargo, si este aumento de peticiones es debido a picos discretos en ciertos momentos de tiempo, el sobrecoste incurrido podría ser aceptable.
Pero no hay que olvidar que estos valores son muy sensibles a la tasa máxima de peticiones que una instancia es capaz de procesar, y a la memoria y duración de la petición en Lambda.
Caso 3: Usuarios humanos y tráfico local
Aunque hemos analizado cómo el coste crece con la escala de la demanda con una carga de trabajo humana planetaria, nos preguntamos si este análisis de coste podría verse afectado si el tráfico estuviera más marcadamente distribuído a lo largo del día, como en el caso de una aplicación regional. Ejemplos de este caso podrían ser una aplicación web para un ayuntamiento, un servicio de transporte metropolitano, etc.
Escenario
Elegimos el holandés en este análisis, como un idioma altamente localizado de wikipedia. Este es el aspecto que presenta su distribución de tráfico en una semana:
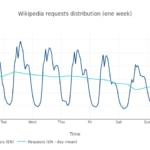
Basándonos en esto, construímos un mes sintético, tal y como hicimos en el ejemplo anterior. Fijémonos en cómo difiere del caso planetario.
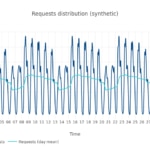
En esta simulación disponemos de un mes sintético para modelar una aplicación regional localizada. La escala (esto es, el número total de peticiones en este mes) es de nuevo 100 millones (38.6 peticiones por segundo, de media). ¿Afecta al coste esta distribución horaria de peticiones, comparada con el caso previo? La respuesta es no. El punto de paridad de coste se alcanza en el mismo rango que antes.
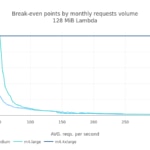
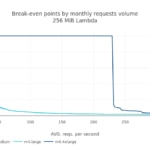
Caso 4: Servicio máquina a máquina
En esta última simulación, intantamos establecer qué factores tienen mayor impacto en el esquema de precios de Lambda y EC2 cuando el tráfico de nuestra aplicacion es producido pro una población de dispositivos que envían peticiones a intervalos regulares. Éste es un caso particular de una aplicación de tipo 'Internet of Things' (por sus siglas en inglés, IoT), como podría ser una red de sensores.
Igual que en simulaciones anteriores, hemos de producir una distribución de peticiones, en este definida por los parámetros explicados a continuación:
- Debería hacer peticiones a nuestro servicio a intervalos regulares, según el parámetro período de dispositivo. Todos los dispositivos contactan al servidor con esta frecuencia.
- Las peticiones de todos los dispositivos en un período dado están repartidas siguiendo una distribución uniforme.
Con este modelo, fuímos capaces de producir un simulador de peticiones que usa el período de dispositivo y el número de dispositivos como sus parámetros de entrada. Con la distribución de peticiones sobre un período de tiempo (período de simulación) como su salida, podemos calcular fácilmente los costes asociados para EC2 y Lambda.
A continuación obtuvimos los perfiles de coste para Lambda así como para diferentes sabores de EC2, con un número cada vez mayor de dispositivos.
Población de dispositivos y período de dispositivo
Más dispositivos producirán una mayor tasa de peticiones en el mismo período. ¿Cómo se relacionan estas cantidades?
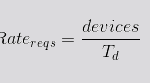
Por ejemplo, con cada dispositivo haciendo una peticion por hora, esto es, un período de dispositivo de 3.600 segundos, el objetivo de 100 peticiones por segundo se alcanza con 360.000 dispositivos.
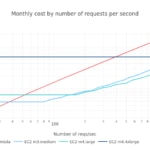
Como en la simulación anterior, un punto de paridad de coste aparece para cada sabor de EC2 que comienza costando menos que su contrapartida en Lambda. Sin embargo, es también notable que con instancias de EC2 más grandes la probabilidad de que éstas sean infrautilizadas es también mayor, aumentando así el desperdicio y, por tanto, el coste.
Observamos que los costes con EC2 son ligeramente mayores que en el modelo teórico. Pero, en general, la relación entre costes es aproximadamente igual, usando un ratio de rendimiento de 1.
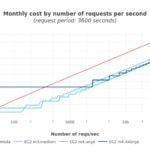
Lambda es más económica con una tasa baja de peticiones (<35 peticiones por segundo con m3.medium, y <50 peticiones por segundo con m4.large). Las instancias de EC2 se vuelven más baratas una vez que la tasa de peticiones aumenta lo suficiente, siendo más baratas las instancias de EC2 más pequeñas que las más grandes, ya que las más grandes desperdiciarán más recursos de media. También ha de notarse que la instancia m3.large es más cara que las m4.*, y de hecho ya es un tipo obsoleto.
Aplicando actividad de temporada
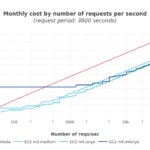
Más allá de modelar el tráfico con una distribución uniforme sencilla, también consideramos variaciones debido a actividad de temporada, permitiéndonos explorar cómo ésta afecta al coste.
Para el análisis, impusimos arbitrariamente una distribución de tráfico con un gran pico al principio del mes, y otro pico de la misma altura, pero más ancha en tiempo, al final del mes.
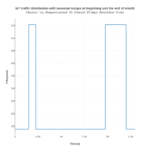
El pequeño pico en coste en instancias EC2 corresponde con subidas puntuales de tráfico, y puede ser explicado por los grupos de autoescalado generando más instancias para absorber el exceso de tráfico mientras dure, aumentando por tanto el coste de manera temporal.
Conclusiones
- La distribución de tráfico tiene un impacto considerable en el punto de paridad de coste. Hemos visto como una distribución uniforme the peticiones alcanza antes dicho punto de paridad de coste en términos de tasa media de peticiones que cuando la forma del tráfico sigue una distribución más natural.
- Con perfiles de tráfico donde las peticiones llegan en intervalos periódicos, y un número total de peticiones pequeño, la arquitectura 'serverless' parece ser una buena elección en términos de coste, velocidad de despliegue y esfuerzo. De esta manera, Lambda es probablemente la solución a elegir si nuestra aplicación tiene períodos de inactividad suficientemente largos.
- Una vez que se alcanza el punto de paridad de coste, cuando EC2 es más económico que Lambda, la diferencia de coste crece rápidamente, haciendo a Lambda cada vez menos atractiva en términos de coste. Es, por tanto, de gran importancia conocer si el volúmen de tráfico esperado estará cerca del punto de paridad de coste.
- No hemos de subestimar el ahorro asociado al apalancamiento de la infraestructura HTTP del proveedor de 'cloud'. Análogamente, el ahorro en la planificación y despliegue de alta disponibilidad puede levantar el punto de paridad de coste mucho más allá de donde lo hemos puesto en nuestros estudios teóricos, haciendo Lambda muy económico.
- Hemos de ser conscientes de la reducción de velocidad de CPU que tendremos con los sabores de Lambda con menor cantidad de memoria. Si nuestro código está limitado por la CPU, elegir los sabores con menor cantidad de memoria puede que no sea una viable, ya que los tiempos de ejecución, y por tanto la latencia, pueden crecer más allá de nuestros requisitos. Por otro lado, si nuestro código está limitado por la E/S, la reducción de velocidad de la CPU puede que no nos afecte significativamente.
- El punto de paridad de coste (si es que lo hay, esto es), depende fuertemente de la aplicación misma. Sin realizar medidas del código de aplicación objetivo, sin saber el uso esperado del servicio, el SLA y las capacidades del equipo a cargo de construir la aplicación, resultará prácticamente imposible discernir qué arquitectura, Lambda o EC2 es más interesante.