Construyendo un log verificable, parte 1: ideas principales
El problema de la verificación de la integridad de los datos en un tema clásico que ha sido bien estudiado en las últimas décadas. Muchos sistemas de base de datos o de log corren sobre servidores no confiable o están expuestos a ataques maliciosos por parte de personal propio y, por tanto, son vulnerables a manipulación indebida. Con el advenimiento de la computación en la nube y la posibilidad de tener que tratar con datos confiados al exterior, tal situación se ha visto agravada. Este problema es un desafío esencial para las instituciones financieras donde la preservación de la corrección de los datos de cliente y las transacciones es crucial en términos de cumplimiento legal y reputación.

Construir un sistema capaz de hacer evidente cualquier modificación no autorizada a un conjunto de datos almacenados no es una tarea fácil. Tal como se verá, los enfoques tradicionales y experimentales tienden a adolecer de una falta de rendimiento fundamental bajo cargas de trabajo intensivas en escritura debido a limitaciones de concurrencia. En esta serie de artículos, compartiremos nuestra experiencia construyendo una posible solución desde cero. Exploraremos los tipos de estructuras de datos disponibles y el proceso que seguimos para seleccionar las más adecuadas. Además, discutiremos las decisiones clave que conciernen a cualquier sistema de base de datos, tales como el almacenamiento, modelos de consistencia, replicación, etc. Todas nuestras elecciones están reflejadas en un proyecto que hemos denominado QED[1].
En esta primera parte de la serie, introducimos en detalle el problema a resolver y revisamos los enfoques académicos e intuiciones que nos condujeron hasta una estructura de datos apropiada: una que nos capacita para auditar la corrección manteniendo a su vez la eficiencia.
Introducción
Podríamos decir que la integridad de una colección de datos queda preservada si podemos asegurar que tales datos no han sido modificados por un usuario desconocido de una manera no autorizada. Ésta es una característica esencial en el ámbito de muchas actividades que recolectan información de usuario crítica, tal como la banca o servicios sanitarios. Podemos imaginar un buen número de situaciones donde, bien un atacante malicioso, o bien un empleado de la casa, puede realizar actividades no registradas y/o modificar los datos previamente almacenados.
Las organizaciones tienden a usar sistemas de base de datos generales y ampliamente conocidos para almacenar sus datos e intentan limitar el tipo de operaciones que los usuarios pueden realizar sobre ellos, por medio de mecanismos de autenticación y control de acceso. Una estrategia habitual para asegurar un sistema es reducir su superficie vulnerable. Esto implica implementar el hardening de los servidores para proteger el sistema frente a ataques conocidos. O incluso usar hardware confiable —trusted hardware— para alojar aplicaciones críticas. Sin embargo, estos mecanismos pueden resultar insuficientes para asegurar completamente la integridad de los datos y, en último término, el propietario de los datos tendrá que realizar un acto de confianza sobre la correcta configuración y operación del servicio por parte de los usuarios privilegiados. Cuando se produce una brecha, el análisis forense es la única herramienta a la que pueden recurrir, la cual tiene una naturaleza reactiva.
Respecto a la relación con el cliente, dicha insuficiencia fuerza a las organizaciones a intentar preservar un estado de confianza respecto a la integridad de los datos que recogen. Pero, en último término, un cliente airado, o incluso uno malicioso, podría exigir pruebas, o hacer acusaciones espúreas de corrupción en los datos, y emprender medidas legales.
Todas estas razones son las que motivan la exploración de un mecanismo de verificación para preservar la integridad de los datos.
Una cuestión de auditoría
Es práctica habitual capturar la variedad de amenazas, abusos y patrones a los que un sistema está expuesto, y las técnicas necesarias para prevenirlas, en lo que se conoce como modelo de ataque. Un modelo de ataque resulta útil para ayudarnos a pensar como un atacante. Mientras que la mayoría de los enfoques en seguridad asumen una noción relajada del atacante, el problema con el que nos enfrentamos precisa de una más severa: esto es, un atacante perteneciente al personal interno con acceso total y conocimiento sobre el servidor donde residen los datos, incluyendo la capacidad de gestionar todos los elementos criptográficos. Esto significa que el servidor es completamente no confiable. Se puede deducir que este modelo de ataque, centrado en los empleados, engloba el modelo basado en un atacante externo.
La principal consecuencia de asumir este modelo de atacante interno (dado que no es práctico impedir la alteración de registros digitales) es que desplazamos nuestro foco de la prevención a la detección. Para conseguir detectar las manipulaciones indebidas habremos de almacenar tales registros en algún tipo de estructura de datos que debe cumplir una serie de condiciones cruciales. Las explicaremos más adelante, pero primero, establezcamos y clarifiquemos los elementos que configuran nuestro escenario.
Supongamos que tenemos una secuencia contínua de registros: registros de acceso, registros de eventos, registros de transacción, o, para el caso, cualesquiera datos secuenciables. Tal secuencia puede ser materializada en uno o varios ficheros de log y proporcionar así una pista de auditoría para entender la actividad de un sistema. Por tanto, puede estar sujeto a consulta por los usuarios que quieran diagnosticar problemas en el mismo. La evidencia que uno busca en este tipo de investigaciones de diagnóstico a menudo toma la forma de declaraciones de existencia y orden. Pero este tipo de logs cuya manipulación indebida resulta evidente (tamper-evident logs en inglés), también han sido empleados en otros casos de uso tales como la construcción de sistemas de ficheros versionados, protocolos peer-to-peer, o como un mecanismo para detectar inconsistencias entre réplicas en un sistema distribuído.
Podemos identificar tres agentes en nuestro esquema: una fuente o autor, que genera logs de datos y debe ser confiable por definición; un logger, que materializa y mantiene el log; y uno o varios auditores.
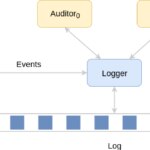
Dado que estamos asumiendo que el logger nunca es confiable, y es libre de mentir al generar resultados en respuesta a consultas, la manipulación indebida no puede ser detectada a menos que un auditor confiable —al menos uno— lo esté auditando. Esta situación nos lleva a enfatizar la necesidad una auditoría contínua para garantizar la corrección. La auditoría debe ser por tanto una operación frecuente y, por consiguiente, debe ser optimizada en términos de rendimiento.
Pero, ¿cómo puede un auditor cumpir su misión? Podemos ver que el proceso de auditoría involucra dos roles: demostrador y verificador. El logger desempeña el papel del demostrador. Almacena los datos y responde a consultas sobre ellos. En respuesta a estas consultas, devuelve un dato que sirve como prueba de la validez de la respuesta. Esa prueba puede ser comprobada eficientemente por un verificador. El auditor desempeña el papel del verificador. Hace consultas al demostrador y verifica los resultados haciendo uso de la prueba.
Para dar apoyo a este escenario, el logger necesita implementar un tipo especial de estructura de datos cuyas operaciones, en respuesta a consultas de los usuarios, pueden ser realizadas por demostradores no confiables. Tal estructura de datos ha sido formalizada en detalle y denominada como estructura de datos autenticada (ADS, por sus siglas en inglés) [2]. Las ADSs son, por consiguiente, el elemento principal a explorar en nuestra intención de permitir trasladar los datos a servidores no confiables sin perder la integridad de los mismos.
Elementos constituyentes esenciales
El problema de revocación de certificados [3, 4] en infraestructura de clave pública motivó trabajos tempranos sobre los ADSs. La mayoría de estas obras se apalancan en dos primitivas criptográficas como elementos constituyentes para transformar estructuras de datos regulares en ADSs como tales: funciones hash criptográficas y firmas digitales. Las funciones hash operan como mecanismos seguros de compresión. Mapean el inmenso espacio de posibles registros con un espacio más reducido de resúmenes criptográficos. Las colisiones, aunque teóricamente posibles, son computacionalmente hablando difíciles de hallar. Por su parte, las firmas digitales proporcionan las características de autenticidad, no-repudio e integridad de los registros, lo que suministra al firmante un mecanismo para prevenir la falsificación a la vez que capacita a terceras partes para su verificación.
Combinando ambas técnicas, un registrador no confiable podría producir un flujo de compromisos —commitments— firmados en respuesta a un flujo de eventos como entrada, generando un compromiso firmado para cada evento que se añada al log. Ésta es una de las primeras aproximaciones a los ADSs que podemos imaginar: una cadena de hashes —hash chain— donde cada compromiso captura el log completo hasta ese momento. Esta técnica nos permite establecer un orden demostrable entre entradas y asegurar que cualquier compromiso de un estado dado del log es, implícitamente, un compromiso de todos sus estados previos. Por tanto, cualquier intento subsiguiente para eliminar o alterar alguna entrada en el log invalidará la cadena de hashes.

Para demostrar que una entrada ha sido incluída en la cadena y que no ha sido modificada de una manera inconsistente, habremos de producir tres tipos de prueba:
- Prueba de inclusión, que responde a la pregunta de si una entrada dada está en el log o no.
- Prueba de consistencia, que responde a la pregunta de si una entrada dada es consistente con las anteriores. Esto asegura que la historia registrada no ha sido alterada.
- Prueba de borrado, de manera que somos capaces de saber cuándo un registro ha sido manipulado indebidamente en su ubicación de origen.
Desafortunadamente, las cadenas de hash no son ADSs muy eficientes. Presentan un comportamiento lineal en espacio y tiempo (O(n)) porque precisan que los auditores examinen todos los eventos entre snapshots de la cadena de hashes para una simple consulta de membresía —membership—. Aunque se han propuesto otras estructuras de datos que mejoran las cadenas de hashes (p.ej., las listas por saltos [5]) —skip lists—, la investigación en transparencia de certificados se centró en diccionarios autenticados, produciendo un esquema de árbol de hashes basado en el trabajo de Ralph Merkle.
Un árbol de hashes o árbol de Merkle es un tipo de árbol binario que usa funciones hash criptográficas y tiene un largo historial de usos en la implementación de datos estáticos autenticados. En un árbol de Merkle, las hojas almacenan registros de datos y computan su propio hash. Los nodos padre derivan su hash computando una función hash de los hashes de sus hijos concatenados de izquierda a derecha. El hash raíz es pues un resumen de todo su contenido que haría evidente su manipulación indebida. Llamamos a este resumen el compromiso de ese árbol.
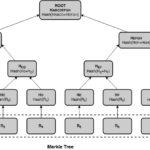
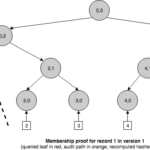
Los árboles de Merkle son estructuras de datos muy interesantes para nuestros propósitos. Puesto que almacenan datos únicamente en las hojas, su uso del espacio es lineal, y debido a que son árboles binarios, la longitud de un camino desde la raíz a las hojas es logarítmico con el tamaño del árbol. Esta propiedad confiere un acceso aleatorio eficiente a las hojas, pero también permite la construcción de pruebas de membresía eficientes. Las pruebas de membresía solicitan que el logger demuestre si un evento en particular existe en el árbol y que éste es consistente con un compromiso ya publicado. Estas pruebas incluyen lo que se conocen como rutas de auditoría de Merkle —Merkle audit paths—.
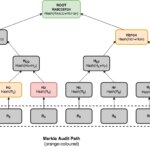
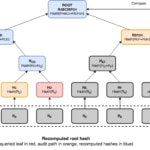
Una ruta de auditoría para una hoja está compuesto de todos los nodos adicionales necesarios para computar el hash raíz de ese árbol. Podemos ver que la ruta de auditoría mínima incluye un nodo por cada capa del árbol, haciendo el tamaño de la prueba O(log n). Dado que una ruta de auditoría es un tipo de árbol podado, también presenta tiempos de consulta y verificación eficientes en O(log n). Una ruta de auditoría puede verificarse recomputando todos los hashes, de abajo a arriba, desde las hojas hasta el nodo raíz. Una vez que hemos recomputado el hash raíz, podemos compararlo con el hash del nodo raíz original del árbol de Merkle (el compromiso). Si ambos encajan, entonces la prueba se cree que es válida, siempre que tengamos disponible un hash raíz de fiar para compararlo. Podemos lograr este objetivo combinando árboles de hashes con el uso de firmas digitales para que una parte confiable firme los compromisos.
Desventajas de los árboles de Merkle
Aunque un árbol de hashes llano tiene propiedades útiles para implementar diccionarios autenticados estáticos, no puede satisfacer las que surgen al enfrentarse con un escenario dinámico. Podemos ver que permite eficientemente operaciones de consulta con su correspondiente prueba, pero precisa reconstruir completamente el árbol en cada operación de actualización. Puesto que cada operación lee, y posiblemente actualiza, la raíz del árbol de hashes, la concurrencia se ve limitada y, por tanto, el rendimiento reducido significativamente. Bajo cargas de trabajo concurrentes intensivas en actualizaciones esta situación se ve magnificada.
Los escenarios de actualización muestran otra limitación importante del árbol de hashes: cuando realizamos una operación de actualización perdemos la información necesaria para reconstruir versiones pasadas de ese árbol. Cuando un ADS es capaz de capturar su historia de cambios, se dice que es persistente. Éste es un requisito fundamental al construir un log, donde los datos son secuenciados. En un log existe una noción débil de tiempo debido a la ordenación en la inserción de registros: para una entrada dada, las entradas a su izquierda son «más antiguas» que las entradas a su derecha. Una cadena de hashes puede cumplir fácilmente esta ordenación debido a su naturaleza encadenada pero, ¿cómo podemos lograr este requisito con un árbol de Merkle?
Hemos visto previamente que un árbol de hashes almacena los registros en las hojas, pero no hemos dicho nada acerca de la posición que los registros ocupan en el nivel inferior de la estructura arbórea. Si rellenamos los registros de izquierda a derecha en ese nivel, a la vez que mantenemos el orden de inserción, podríamos reproducir el comportamiento de un log. Un árbol binario que se comporta de esta manera se llama árbol binario completo. Un árbol binario es completo si todos sus niveles están completamente rellenos excepto quizá el último nivel, y en ese el nivel más bajo, las hojas se rellenan de izquierda a derecha.
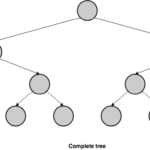
Esta combinación de un árbol de Merkle y un árbol completo es lo que Crosby y Wallach denominaron un árbol histórico —history tree—[6].
Árbol histórico
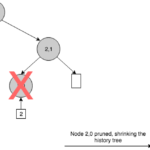
En resumidas cuentas, un árbol histórico es un un árbol de Merkle versionado donde los registros se almacenan de izquierda a derecha en el nivel más bajo, siguiendo un modelo de sólo-agregar —append-only—. Como una cadena de hashes, este ADS es naturalmente persistente, con la diferencia de que permite pruebas de membresía eficientes. En cada inserción, genera un nuevo árbol de Merkle con un número de nivel posiblemente mayor y, después, computa un nuevo hash raíz que sirve como una snapshot de todo el log en ese punto de la secuencia. Podemos ver que un árbol histórico crece siempre de izquierda a derecha. Esta propiedad de crecimiento nos permite hacer declaraciones eficientes acerca del pasado porque podemos reconstruir versiones antiguas del árbol podando ramas específicas de derecha a izquierda.
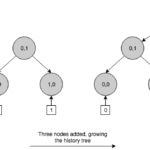
Los nodos en un árbol histórico se identifican por un índice y una capa (Ni,l). El índice se corresponde con una versión específica del árbol. Puesto que la capa de las hojas corresponde a la capa 0, un nodo hoja se identifica por la nueva versión del árbol, producida cuando se inserta el evento asociado a esa hoja, y una capa de 0, es decir, Ni,0. Los nodos interiores toman el índice a partir del valor del índice del último descendiente más a la izquierda. Por ejemplo, un árbol de versión 5, tiene 6 eventos almacenados en la capa 0 (del 0 al 5) y una profundidad de 3. Podemos observar que este árbol no está completamente relleno porque un árbol de profundidad 3 puede almacenar un máximo de 23 eventos en las hojas. Si excedemos ese número, el árbol crecerá en profundidad hasta 4, y así sucesivamente.
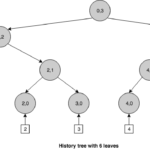
A diferencia de un árbol de Merkle ordinario, un árbol histórico puede producir pruebas de membresía que permiten verificar si un evento en particular está presente en el log y es consistente con el compromiso actual, pero también con los compromisos del pasado. Por ejemplo, podríamos demostrar que el evento insertado en la versión 1 era consistente con la versión 1 y además está aún presente en la versión 5.
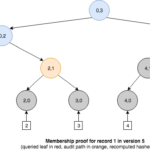
Además de las consultas de membresía, un árbol histórico también nos capacita para generar un nuevo tipo de prueba denominada prueba incremental —incremental proof—, que puede usarse para mostrar la consistencia entre compromisos para diferentes versiones del árbol. Esto es, todos los eventos en la versión anterior están presentes en la más reciente. Para lograrlo, la prueba debe devolver sólo la información necesaria para reconstruir ambos hashes raíz de manera que puedan compararse con los compromisos publicados.
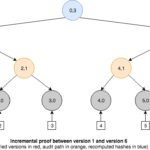
Pero no todo es perfecto para nuestras necesidades. Podemos observar que puesto que un árbol histórico almacena los resúmenes criptográficos de los eventos en las hojas, no permite la búsqueda eficiente de resúmenes criptográficos por su contenido, ya que están ordenados por su momento de inserción en vez de lexicográficamente. Esta propiedad resulta esencial para construir lo que se llama árbol binario de búsqueda (BST, por sus siglas en inglés). Un BST precisa que el valor de cada nodo sea mayor (o menor) que el valor de su hijo izquierdo (o derecho), esto es, implica la existencia de un orden lexicográfico que permita las operaciones de búsqueda usen la técnica de divide y vencerás conocida como búsqueda binaria. Como vimos anteriormente, cada nodo se etiqueta con dos valores que conforman una clave: un índice y una capa. Este índice puede usarse para navegar por el árbol usando el algoritmo de búsqueda binaria, pero es insuficiente para producir una pruebas de membresía basada sólo en el evento original. Necesitaríamos disponer de algún mecanismo capaz de mapear el hash del evento original a la versión de dicho evento en el árbol histórico.
Podemos identificar un problema similar con pruebas de «no membresía». Incluso disponiendo de un mecanismo de mapeo entre resúmenes criptográficos de eventos y versiones, no hay forma de generar una ruta de auditoría para eventos que no están presentes en el árbol histórico. Para conseguir esta consulta, necesitaríamos recorrer la lista entera de hojas para asegurar que un evento en particular no existe en el árbol. Pero resulta obvio que tal operación es tan ineficiente como su correspondiente en la cadena de hashes.
Así que ahora tenemos que enfrentarnos con dos desafíos fundamentales: cómo mapear resúmenes criptográficos a versiones en el árbol histórico para poder producir pruebas de membresía, y cómo generar eficientemente pruebas de «no membresía». En la siguiente parte de la serie veremos como nos las arreglamos para superar estos problemas.
Referencias
[1] QED
https://github.com/BBVA/qed
[2] R. Tamassia. Authenticated data structures. In 11th Annual European Symposium on Algorithms, Sept. 2003.
https://cs.brown.edu/research/pubs/pdfs/2003/Tamassia-2003-ADS.pdf.
[3] Laurie, B., Kasper, E. Revocation transparency. Google Research (2012),
http://www.links.org/files/RevocationTransparency.pdf.
[4] Laurie, B., Langley, A., Kasper, E. Certificate Transparency. RFC 6962 (2013),
http://tools.ietf.org/html/rfc6962.
[5] Goodrich, M., Tamassia, R., and Schwerin, A. Implementation of an authenticated dictionary with skip lists and commutative hashing. In DARPA Information Survivability Conference & Exposition II (DISCEX II) (Anaheim, CA, June 2001), pp. 68–82.
https://cs.brown.edu/cgc/stms/papers/discex2001.pdf.
[6] Crosby, S.A., Wallach, D.S. Efficient Data Structures For Tamper-Evident Logging. In USENIX Security Symposium. pp. 317–334 (2009),
http://tamperevident.cs.rice.edu/papers/paper-treehist.pdf.