Acelerando el entrenamiento de redes neuronales con MxNet y máquinas de AWS
Las técnicas de aprendizaje profundo o 'deep learning' nos ofrecen unos resultados espectaculares en diversos campos del aprendizaje automático, o 'machine learning'. Sin embargo, el entrenamiento de una red neuronal compleja con un conjunto de datos ('dataset') grande puede llevarnos una gran cantidad de tiempo. Por tanto, acelerar en lo posible el entrenamiento de los modelos de aprendizaje profundo resulta esencial, pero también supone un desafío.

En BEEVA Labs hemos realizado algunos bancos de pruebas internos con diferentes implementaciones de modelos de clasificación de imágenes: en Tensorflow, Keras+Tensorflow y MxNet. Nuestros primeros experimentos estaban centrados en los típicos conjuntos de datos de MNIST y CIFAR10, en los que comparábamos diferentes infraestructuras en la nube preparadas para usar GPUs (unidades de procesado gráfico). Compartimos nuestras primeras conclusiones sobre los factores que afectan al rendimiento y la eficacia del entrenamiento.
Curiosamente, una de las principales enseñanzas que extrajimos fue que debíamos dejar de evaluar redes neuronales en escenarios con los conjuntos de datos habituales como los MNIST o CIFAR10. Como describimos en nuestras primeras conclusiones en detalle, nos encontramos con un conjunto de datos demasiado pequeño como para llegar a saturar la capacidad de las GPUs modernas.
En los posteriores experimentos que llevamos a cabo, hemos intentado una aproximación más práctica, enfocada en el ajuste de modelos ya entrenados, con nuevos datos. La finalidad de estos experimentos es también medir el ratio coste-eficiencia del escalado en paralelo de datos con múltiples GPUs con MxNet en instancias de Amazon Web Services (AWS). Todo esto para complementar nuestra investigación anterior presentada en el post anteriormente mencionado, y para extender el análisis a algunos aspectos que afectan a la escalabilidad.
Ajuste fino con MxNet de modelos pre-entrenados en instancias P2 de AWS
El conjunto de datos de ImageNet tiene más de un millón de imágenes divididas en 1000 clases, y el conjunto completo de imágenes (Imagenet11k), con 10.000 categorías es diez veces más grande. Normalmente no es necesario entrenar un modelo con todo el conjunto de datos de ImageNet como hacen los grupos de investigación de Facebook o Google; y y no suele ser normal tener un conjunto de datos tan grande. En nuestro caso es mucho más práctico realizar un ajuste fino de un modelo ya entrenado. Es más, entrenar el conjunto de datos completo tiene un coste computacional muy alto. Por ejemplo, un solo experimento para entrenar un modelo actual de ResNet en ImageNet durante 100 ciclos (epochs) en la nube pública costaría cientos de euros, y duraría días enteros si no dispusiéramos de una implementación e infraestructura altamente escalable. Sin embargo, como veremos, usar un modelo pre-entrenado en Imagenet y ajustarlo a un conjunto de datos pequeño puede hacerse en cuestión de minutos. Todo ello con suficiente exactitud y un coste menor de 2,5 Euros.
El ajuste de un modelo con datos nuevos está ligado al concepto de transferencia de aprendizaje. En vez de entrenar el modelo desde cero, reemplazamos la última capa de la red neuronal con una nueva que saque el número de clases deseado. Es una alternativa mejor que evitar el sobreajuste si no tenemos suficientes datos; y es también una manera barata de tener los beneficios de los modelos complejos pre-entrenados con grandes conjuntos de datos. Sin embargo, no es la panacea y no podemos emplearlo en todos los casos.
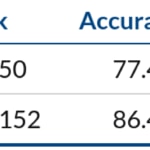
Hemos seguido el ejemplo de MxNet, usando un modelo pre-entrenado con ImageNet11k con una arquitecura ResNet, y realizando el ajuste de este modelo para el conjunto de datos Caltech256, mucho más pequeño. Según la documentación de MxNet, los últimos resultados con el conjunto de datos de Caltech256 obtienen una exactitud del 86,4% con Resnet-152.
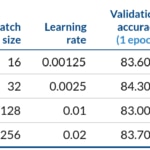
Ajuste de un modeo ResNet152 pre-entrenado en Imagenet11k con MxNet. Rendimiento cuando se escala de 1 GPU K80 en una instancia p2.x a 8 GPUs en una instancia p2.8x.
Hemos realizado el experimento en el siguiente escenario:
- Instancias: {p2.x, p2.8x}
- Modelo: ResNet152
- GPUs: {1, 8}
- Tamaño del batch: {16, 32} x #GPUs
- Tasa de apendizaje (learning rate)= {0.00125, 0.0025} x #GPUs
- Configuración por omisión: "optimizer=sgd"…
Para ejecutar los experimentos en la AMI Deep Learning AMI Ubuntu Linux - 2.4_Oct2017 (ami-37bb714d), con MxNet v0.11.0, y CUDA-8:
$ cd src/mxnet/example/image-classification $ ./data/caltech256.sh $ python fine-tune.py --pretrained-model imagenet11k-resnet-152 --gpus 0 --data-train caltech256-train.rec --data-val caltech256-val.rec --batch-size 16 --num-classes 256 --num-examples 15240 --num-epochs 1 --lr 0.00125
Como ejemplo, con una p2.8x, que usa 8 GPUs con un tamaño de batch de 32 x 8, y una tasa de aprendizaje de 0.02:
$ python fine-tune.py --pretrained-model imagenet1k-resnet-50 --gpus 0,1,2,3,4,5,6,7 --data-train caltech256-train.rec --data-val caltech256-val.rec --batch-size 256 --num-classes 256 --num-examples 15240 --num-epochs 1 --lr 0.02
Después de completar un ciclo, obtuvimos una exactitud de validación entre el 83% y el 83,4%, con una degradación de la exactitud entre el mejor y el peor caso por debajo del 1%. Además, obtuvimos una eficiencia del escalado del 96% escalando a 8 GPUs y una mejora de 7,7x cuando teóricamente podríamos esperar una mejora del 8x en relación a 1 GPU.
Una de las primeras cosas que debemos comprobar es que no tenemos un cuello de botella en la lectura de los datos. Para este propósito, los ejemplos de clasificación de MxNet nos proveen de la opción test-io y confirmamos que la tasa de datos es lo suficientemente rápida. Incluso con 3 hilos decodificando, la tasa era mayor de 1.500 imágenes por segundo.

Ajuste del modelo ResNet152 pre-entrenado en Imagenet11K con MxNet. Rendimiento cuando se escala de 1 GPU K8 en una instanci p2.x a 8 K80 en una p2.8x.
Después de 6 etapas en una p2.8x hemos conseguido en aproximadamente 10 minutos una exactitud de validación del 86,5%, similar al estado de la técnica actual. Añadiendo otros 10 minutos que fueron necesarios para poner en marcha el entorno, la infraestructura nos ha costado menos de 2.5€ con precios on-demand de AWS.
También cambiamos el modelo a ResNet50 pre-entrenado con Imagenet1k. En este caso, después de 6 ciclos, obtuvimos una exactitud de validación del 75,5%, y una eficiencia del 95% escalando a 8 GPUs. En general, los modelos con menos complejidad de computación (en relación al número de parámetros que comparten) pueden conseguir ratios de eficiencia menores.
Ajuste fino de un modelo ResNet152 pre-entrenado en Imagenet11k con MxNet. Rendimiento escalando de 1 GPU K80 en una instancia p2.x a 8 K80 en una p2.8x.
De Kepler a Volta
Todos los experimentos anteriores se han basado en instancias P2 con GPUs Nvidia Tesla K80l, las GPUs más populares del mundo, según la propia Nvidia. Tesla K80 es la GPU más usada en la nube pública. De hecho, a fecha de Diciembre de 2017, es la única GPU disponible en los tres proveedores de nube pública más populares: Amazon Web Services, Microsoft Azure y Google Cloud Platform.
Sin embargo, la arquitectura Kepler fue presentada en 2012. Tesla K80 fue lanzada hace tres años. Y después de Kepler vinieron Maxwell, Pascal y... ¡Volta!
La arquitectura Volta está disponible en AWS usando las nuevas instancias P3 de EC2 desde Octubre de 2017. Las P3 incorporan de 1 a 8 Tesla V100. Las principales característias de estas instancias están descritas en la tabla siguiente.
Los precios de tipo bajo demanda (on-demand) están entre los 2.4€/hora para las p3.2xlarge y los casi 20€/hora para las p3.16xlarge. Es aproximadamente tres veces más caro que sus análogas P2 con el mismo número de GPUs.
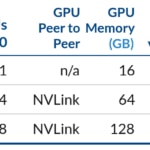
Instancias de AWS EC2 p3.2xlarge, p3.8xlarge y p3.16xlarge. - https://aws.amazon.com/es/ec2/instance-types/p3/
Además, las instancias p3 de AWS, al igual que las supercomputadoras Nvidia DGX, permiten usar contenedores optimizados de Nvidia GPU Cloud. Como curiosidad, el precio actual de DGX-1 con 8 V100 es de 149.000 dólares.
Desde el 4 de diciembre, las GPUs TITAN soportan también los Nvidia GPU cloud containers. Por tanto, ahora podemos también usar estos contenedores desde nuestros PCs, y también con las potentes, relativamente comunes y baratas GPUs GeForce® GTX Titan X Pascal.
Ajuste fino de modelos pre-entrenados con instancias P3 de AWS
Repetimos nuestros experimentos de ajuste con estas instancias P3, para comparar con los resultados anteriores obtenidos con las instancias P2. Para ello usamos las NVIDIA Volta Deep Learning AMI, con el contenedor optimizado MxNet de NVIDIA GPU Cloud nvcr.io mxnet:17.10 corriendo en CUDA-9.
Escenario:
- modelo: ResNet152
- instancias: {p3.2x, p3.8x}
- GPUs: {1, 4}
- Tamaño del batch: {16, 32} x #GPUs
- Tasa de aprendizaje = {0.00125, 0.0025} x #GPUs
Realizamos el ajuste al modelo pre-entrenado ResNet152 con tamaños de lote de 16 y 32 imágenes. Instancias p3.2x y p3.8x.
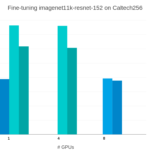
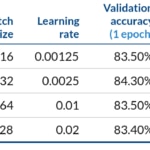
Ajuste fino de un modelo ResNet152 pre-entrenado en Imagenet11k con MxNet. Rendimiento cuando se escala de 1 GPU V100 en una p3.2x a 4 V100 en una p3.8x
Con los precios on-demand de AWS, no sólo el rendimiento es mucho mayor, sino que también es más efectivo en coste.
Sin embargo, la escasez de las instancias P3 de AWS por el momento hacen que sus precios en el modo spot sean muy volátiles. Especialmente para las instancias p3.16xlarge, donde incluso se pueden encontrar precios más alto que en el modo bajo demanda. Es más: es común encontrarnos con los mensajes de error capacity-not-available cuando intentamos usar las instancias de tipo p3.8x.
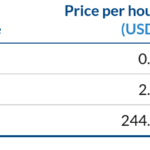
Precios de las instancias EC2 P3 en noviembre de 2017. - AWS
Optimizaciones de NVIDIA GPU Cloud, NCCL y OpenBLAS
Por útimo, intentamos extraer los beneficios del contenedor NVIDIA GPU Cloud MxNet, así como los beneficios del soporte de las bibliotecas NVIDIA Collective Communication Library (NCCL). Para ello usamos la AMI base de aprendizaje profundo (Ubuntu) versión 2.0 en una instancia p3.8xlarge. Esta AMI incluye una instalación de NCCL.
Repetimos el experimento, con ResNet152, usando la versión de código abierto de MxNet, en vez de la versión distribuida en contenedores de NVIDIA. Las primeras pruebas fueron directamente con el paquete python mxnet-cu90, versiones 0.12.0 y 1.0.0.
Para 4 GPUs, los ratios de rendimiento fueron un 15% más lentos para tamaños de lotes de 16x4. Pero fueron menos de un 1% más lentos para tamaños de 32x4.
Es más, hace poco se presentó MxNet 1.0.0 con soporte experimental para NCLL. Según las declaraciones de MxNet, con kvstore='nccl', los usuarios pueden "entrenar un modelo un 20% más rápido en sistemas con varias GPUs" en algunos casos, y debería ser "significativamente más rápido que usando kvstore='device' cuando el tamaño del lote es pequeño".
Para probar esta características, tuvimos que compilar con USE_NCCL=1. Es más, seguimos los siguientes pasos para usar la versión con NCCL instalado, como usuario root:
# mkdir /usr/local/nccl
# cp /lib/nccl/cuda-9/ /usr/local/nccl/lib/ -r
# mkdir /usr/local/nccl/include
# cp /usr/include/nccl.h /usr/local/nccl/include/
# incubator-mxnet
# make -j $(nproc) \
USE_OPENCV=1 \
USE_BLAS=openblas \
USE_CUDA=1 \
USE_CUDA_PATH=/usr/local/cuda \
USE_CUDNN=1 \
USE_NCCL=1 \
USE_NCCL_PATH=/usr/local/nccl/ \
# export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nccl/lib
Sorprendentemente (o no) en este escenario concreto no fuimos capaces de obtener ninguna mejora en particular activando NCCL. Sin embargo, con kvstore nccl, el rendimiento fue incluso entre un 3% y un 4% más lento que con la configuración de kvstore device por omisión.
Sin embargo, compilando MxNet desde el código fuente con USE_BLAS=openblas conseguimos aproximadamente el mismo rendimiento que con el contenedor NVIDIA GPU Cloud.
Conclusiones
Podemos resumir nuestas conclusiones principales, desde el punto de vista científico, de ingeniería e infraestructura en los siguientes puntos:
- Tamaño de lotes (batch size) y velocidad de aprendizaje (learning rate). Los lotes grandes reducen la saturación en las comunicaciones, incrementando el rendimiento. Pero también degradan la convergencia. Recientemente, Facebook AI Research ha propuesto una método para reducir este problema en la práctica escalando progresivamente la tasa de aprendizaje.
- Pipeline de datos. La ingesta de datos y el disco duro pueden ser el cuello de botella principal. Para escalar eficientemente es importante que la implementación tenga en cuenta tanto computación como las comunicaciones.
- Arquitectura. En nuestros experimentos la última arquitectura V100 en instancias P3 era mucho más rápida e incluso más rentable que con las instancias P2 anteriores con arquitectura Kepler.
- Precios. Las instancias spot en AWS suelen ser una forma útil de tener instancias baratas. Sin embargo, las instancias P3 son escasas y sus precios spot son tremendamente volátiles.
- El marco de desarrollo MxNet tiene en cuenta la eficiencia: En nuestros experimentos con MxNet, se consiguieron niveles similares de eficiencia incluso sin las optimizaciones de Nvidia: la biblioteca NCCL y el contenedor NGC. Es más, los ejemplos de clasificación de imágenes con MxNet tienen una forma sencilla de comprobar la existencia de cuellos de botella en la ingesta de datos. Aedmás, la configuración por omisión funciona bastante bien.